An Update To The Dimensional Modelling Article
A couple of weeks ago I posted an article asking whether dimensional modelling was suitable for all types of reporting, even operational, and I got the largest amount of feedback that I'd ever received for an article. The article was in response to a project I was working on where this question had come up, and quite a few people asked me to report back after we put the design together. The work was for a university, so what I'll be talking about are students, registrations, courses, admissions and so forth.
In short, yes we did put together a dimensional model, but the key to it was in some circumstances to "snowflake" the key dimensions, so that we could store facts at different levels of granularity. However, when we first approached it, we kept an open mind and it was only after a day or so that it was clear that a dimensional model would work, which was nice as I'd tried not to be to ideological about it at the start but as time went on it became clear that a dimensional design would work, and would in fact be preferable to a 3NF design.
Right from the start, it seemed obvious to me that there was some benefit in separating data items in the warehouse into those that were "facts" - student admissions, course grades, vacancies advertised, people appointed to posts - and dimensions - students, courses, departments, staff, cost centres and so on. This would make sense whatever model we worked to, even if we didn't formally state that it was a dimensional warehouse, as it would tidy up what would otherwise be a difficult data model to navigate. We carried out some interview and, just as when putting a normal, OLTP system together, identified the key entities and relationships within the data. At the same time, we looked out for natural hierarchies in the data with an eye to how data would later aggregate in the warehouse.
After a couple of days, the list of entities, and the way they related together in hierarchies, looked something like this:

Now, all so far so good, but there were a couple of interesting bits to this, that initially made us feel that a dimension model might not be flexible enough for this customer:
- firstly, the facts - registrations, admissions, grades, assessments and so on - were often stored at differing levels of granularity. For example, students registered on both courses and modules, so a single courses dimension, with module ID the primary key and course details denormalized into the same dimension table, wouldn't work
- secondly, a lot of the operational reporting would be done against what would be higher levels in the dimension, meaning again that if we had a single denormalized dimension table, users would have to work out that a single course would be in the table multiple times, and they'd need to select distinct to return details, and
Still, the essence of a dimensional model was there, but the issue that was causing us a problem was the idea of trying to get all the levels of say the courses dimension into one denormalized dimension table. If we did this, we could only store facts at the lowest level - module - and if users wished to print out lists of courses, not modules, they'd have to be aware that the courses information was denormalized into this table and contained repeated rows.
The trick to it then was down to a comment that David Aldridge made to the original article, where he made the point that, if facts are stored at differing levels of granularity, you may want to normalize your model more. Therefore, what we eventually put together was a snowflake model, rather than a straight star schema, and broke the components of for example the courses dimension - module, course, school, faculty and so forth - into separate tables. By doing this, we kept the various entities in their own tables, making it easier for users to run operational reports, but we kept the basic idea of splitting items into facts and dimensions.
Now to do this, I ended up using Oracle Designer 9i, as OWB 10g doesn't support snowflaked dimensions. I was quite surprised actually at how good Designer was, and certainly in terms of diagramming and modelling it's a lot better than Oracle Warehouse Builder. I ended up putting together models to describe the main facts and dimensions like this:
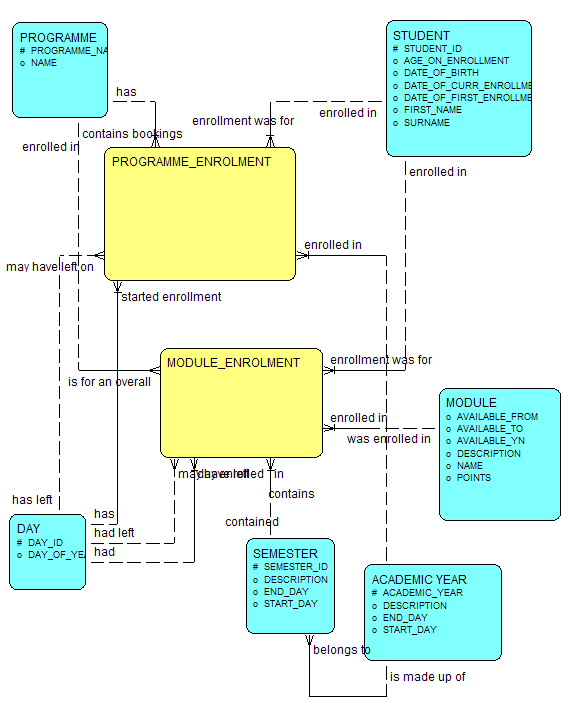
and the main dimensions like this:
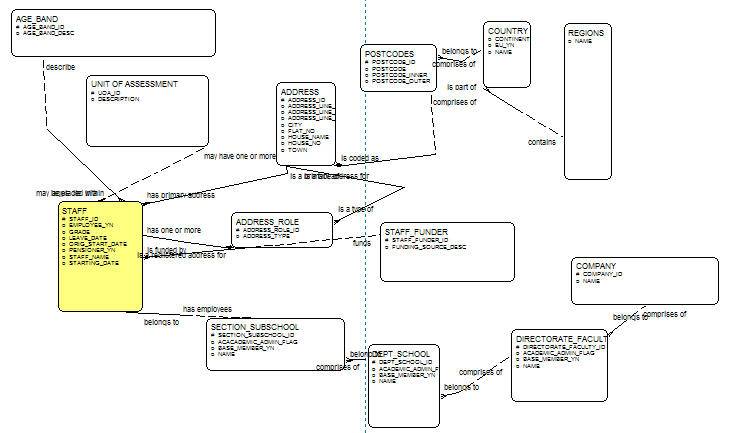
which although normalized, are still keeping true to the dimensional modelling approach.
My next thought was to build up individual dimensions by pulling together the individual entity tables into the relevant dimensions. For example, to create my courses dimension, I would use the CREATE DIMENSION statement to bring together columns from the modules, courses, schools and faculties tables, and to create the staff dimension, I'd use columns from the staff table and the department table, and then reuse columns from the schools and faculties tables. However, I quickly came across the restriction where you can't use a table column in more than one dimension, which scuppered that idea. What this then means is that, if I'm going to use the CREATE DIMENSION statement and create formal dimensions in the database, I'll need to create a modules_dim table that denormalizes the courses and faculties columns into it, and then a courses_dim table that does the same for faculties, and so on. I'll still be able to use the same table building blocks, and I guess it'll only benefit performance as I'll be eliminating table joins at runtime.
So, in summary - yes, we were able to use a dimensional model, even when the organisation generated facts at differing levels of granularity, and where it reported on different levels in the dimension hierarchy, but what we had to do was compromise the dimensional model a little bit and instead normalize the dimensions, which gave us the flexibility we needed. Moreover, by keeping to the dimensional model, we kept the data model simple and hopefully we'll still be able to take advantage of the star schema optimisations in Oracle such as star transformations.
Thanks again to everyone that helped out with this.