More on summary tables
Summary tables are often very suitable candidates for partitioning. They are usually date organised and as we generally receive data for a limited range of dates we are able to apply the changes to a subset of partitions of a table. In particular we can get away from the use of merge or delete/insert type operations against the whole table and replace them with a potentially more efficient truncate partition followed by a bulk insert. If the summary table has bitmap indexes on the dimension keys (and for a DW this quite likely) there is a potential performance problem related to multiple changes to the bitmap indexes. It is far more efficient to disable the index and then rebuild the unusable index partitions after the bulk load. There is also a hidden gotcha around this; if you disable the partition indexes first and then truncate the partition the indexes are rebuilt as part of the truncate process, leading to slower inserts. To get around this we need to disable the partition indexes after the truncate, or, perhaps, disable the indexes before and after the truncate - I have not timed this though, it may well not be worth the effort to disable index partitions twice.
As I mentioned last time, I like the ability of queries to rewrite to materialized views without the user having to do anything special in the code. Even in Oracle 9.2 the rewrite engine can handle a large amount of whacky user code and still manage to rewrite to an appropriate table. It won't manage queries that contain CASE… ELSE constructs but using CASE on its own works. I favour creating my materialized views on pre-built tables. This gives me a bit more flexibility in the management of tables and if I need to I can drop the MV without dropping its container table. To give query rewrite a fighting chance of working you will need to create Oracle dimension objects and have all of the appropriate constraints (but they can be RELY constraints) in place.
It is possible to nest m-views, that is, do an expensive aggregation once and then use that aggregate to create further m-views at yet higher levels of aggregation. There are two potential problems with this approach, both of them their roots in the same aspect of how query re-write works. Suppose you have a base level table that you query, above this are two summaries tables, S1A and S1B. S1A has further summaries built from it, S2A, S2B.
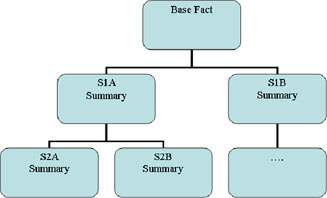
Now submit a query for against the base table that exactly matches the aggregation in S2A; the first thing that happens is the rewrite engine compares S1A and S1B for 'best fit', the level 2 summaries are not eligible for use as they are defined as aggregates of table S1A and not the base table. The optimiser looks for the lowest cost query and then tries to rewrite the rewritten query against the other m-views, now suppose that S1B had a lower cost than S1A then the level 2 m-views will never be used as the query will not match the view definition. The other problem is also related to the fact that the optimiser attempts to re-write rewritten queries. If we have a fully denormalised dimension table and join this to a higher level summary we are no longer joining a single dimension row to the fact table. Suppose our base table joined to geography on city, and our summary joined on state we are likely to have a many-to-many join and this will not work with query rewrite; the work around is to use snowflake design, but this could well have impact on the configuration of query tools. Oracle 10g allows us to define rewrite equivalence (dbms_advanced_rewrite.declare_rewrite_equivalence) which will get around both of these problems; we define our source statements to be denormalised selects from the base table and our target statements to be the nested m-views and hey-presto we have flattened our nesting. In Oracle 9.2 things are much messier and we need to think of bending the way Oracle intended things to work to get the results we need, but that is another story.
Hmm, this page is too big - I'll break into another to finish off