Putting Together a BI Suite Sample Dataset, Part 1
I've more or less finishing the opening chapter of the book I'm working on, and I've reached the part now where I need a set of sample data for the examples that are going to follow. Without giving too much away (the contracts are being signed now), I need a set of data that I can model and then transform, load into an Oracle database and then report on using BI Suite Standard Edition and Enterprise Edition. To properly show off the Enterprise Edition features, I also want to create a set of Microsoft SQL Server data and an Analysis Services cube that I can then transform using Sunopsis Data Conductor, plus I want data in a range of XML, Excel and flat file data sources to bring into the various databases. All of this has to integrate together, and help me create a number of scenarios to show off the features of Discoverer, Answers, Dashboards and Delivers (and ideally, the SOA features in the Fusion Middleware platform) - a fairly ambitious set of objectives.
I took the day off today as leave so that I could try and get the basics of the data model together; I've divided the task into two sections, firstly coming up with the data model, secondly putting some data in it (again, not a trivial task). In the past, and for the seminars I'm currently running, I've put examples together using the sample schemas that come with the database, that come with Analytic Workspace Manager or that come with Siebel Analytics, but for the book I thought I'd put my own dataset together, which has the added benefit of allowing me to shape the examples such that I can show off specific features of the tools - integrating data across platforms, using change data capture, reporting across subject areas and so on.
Anyway, I've based the sample data on a fictional IT software software vendor and services provider (stick to what I know...) called "Porthall Software". Porthall Software uses Oracle Database 10g as it's primary database platform, but has certain sets of sales and customer data on Microsoft SQL Server 2000. Their product catalog is held in an XML document, and certain sets of reference data are on spreadsheets and flat files. Their budgeting application is based on Microsoft Analysis Services, and they use Oracle Warehouse Builder 10g for loading their Oracle databases, and Sunopsis Data Conductor to load other platforms. Finally, they have some legacy HR data in a Microsoft Access database which they want to access via Generic Connectivity, and legacy Orders data that they want to bring over from another Oracle database via Transportable Tablespaces. To make it all work, I'll need a couple of 10g databases and of course SQL Server and Access running alongside - hopefully my Parallels virtual machine with 1.25GB of RAM allocated will be enough.
The source data set starts off with a couple of Oracle schemas:
- PORTHALL_HR, a Human Resources dataset that we'll load via a database link, and
- PORTHALL_ORDERS, an OLTP-style order management scheme that we'll load via a database link, and via asychronous hotlog change data capture.
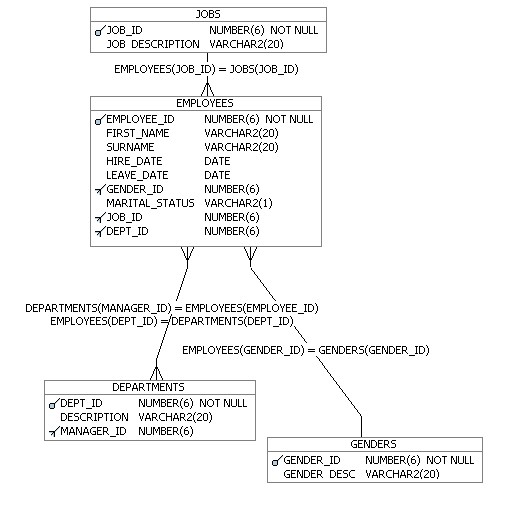
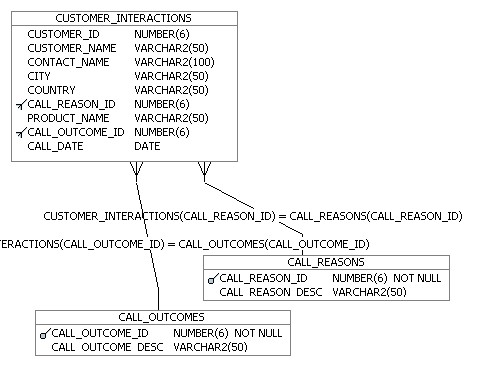
The PORTHALL_ORDERS schema is a bit more complicated, as I want to match it up to other data sets later on - some customer intelligence data that we'll load from spreadsheets using an OWB Expert, and some customer data we'll load in from a CRM system.
The order_stages table is something I'm going to use in the chapter on analytic business processes (BI and SOA); the table holds the dates that an order is at, and I'll put together a BPEL process that calls out to the BI Suite EE BI Server at the "customer credit check" stage.
Incidentally, if you're interested in how I did the table diagrams, it's with a freeware tool called Schemester - it's useful if you've already planned out the table and join definitions, and you want to quickly set the tables and up and generate some diagrams. It's not too clever when it comes to generating the DDL - it seems to keep using the same constraint names which causes errors when you rn the scripts, but I'll just manually edit these myself later and create a single install script for the sample data.
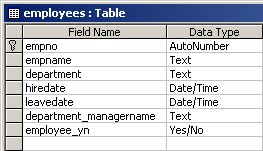
Next I've got a second set of HR data which I'm going to store in Microsoft Access - this is to represent a set of employees who've recently joined via an aquisition, with the point being to show off how data can be integrated (the columns don't match up with the other HR data) and how Generic Connectivity can be used to connect to non-Oracle sources.
To show off how file data can be integrated, there's a set of inventory information in a CSV file.
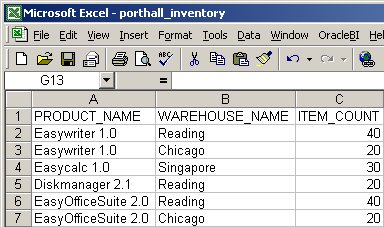
and a set of budget data in an XLS file - OWB can't usually work with XLS files without a whole bunch of work around generic connectivity, whilst the BI Suite EE BI Server will connect directly, and allow you to join to the data without first loading it into the data warehouse.
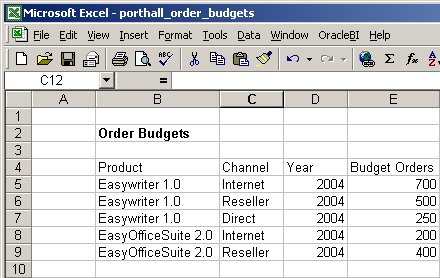
There's going to be another spreadsheet setting out the financial periods, which we'll bring in and then supplement using some derived columns to put together an Oracle OLAP-compatible time dimension. Next, I'll bring in some CRM data from a the PORTHALL_CRM schema in an Oracle database over a database link, with some of the columns deliberately vague (country and city fields left as free-form, customer ID optional, no validation on customer name or contact name) so that I can demonstrate the match-merge and name and address matching in OWB.
The budget forecast data will be in a Microsoft SQL Server 2000 Analysis Services cube; I haven't diagrammed it here as I've not got SQL Server installed yet.
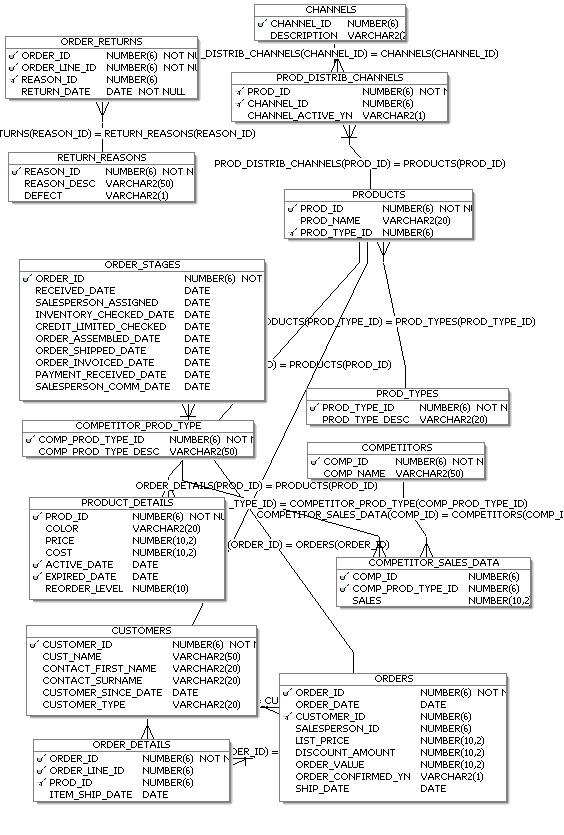
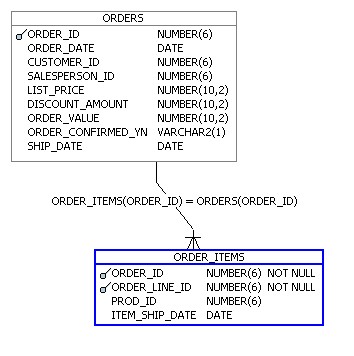
Next, there's some additional orders data from the PORTHALL_ORDERS_LEGACY schema in a legacy Oracle database, that we'll bring over using the transportable modules feature in OWB.
Later on, when I come to build the data warehouse to support BI Suite Standard and Enterprise Edition, I'll create staging, operational (atomic) and analytic layers, and we'll copy some of the data across to the SQL Server database containing the Analysis Services budgets cube to test out the features of Sunopsis Data Conductor, and to show BI Suite Enterprise Edition running against Oracle and SQL Server data at the same time.
The final bit of source data will be a product catalog in XML format. I'll be using this later on to supplement the data in the Oracle data warehouse, and I'll bring it into the BI Server to see how it handles XML data.
So that's it for the source data design. The next steps are to design the target schemas, and then to go back to the source tables and start populating them, with the reference data being keyed in and the sales, inventory and budget data being created programmatically (hopefully...). We're not doing performance tuning, so large volumes of data aren't essential, but I think the most difficult thing will be to make the data "make sense", and to add some quirks and interesting bits into it so that I can point to "insights" that the various tools provide. Anyway, I thought you might be interested in seeing how I put the sample data together, if you've got any suggestions on other things to add in, let me know. Hopefully later in the week, I'll look at the target schemas and plan out some of the features I'll be looking to show off.