In-Memory Parallel Execution in Oracle Database 11gR2
If you've been following this blog and read the posting last year on QlikView, you'd have seen some of the possibilities around the idea of in-memory execution of queries. As desktop PCs, laptops and servers now routinely come with 4GB+ of RAM (going up to 64GB+ for servers) much of what used to have to be done on disk can now be done in memory, eliminating much of the bottleneck around disk I/O. If you followed the announcements around Oracle Database 11g back in the summer of 2009, you might also have noticed something similar sounding for the database, where parallel queries running in one or more database instances could use the RAM available to them to analyze data in memory, in a feature that was called "In-Memory Parallel Query". So what does this feature do, and how does it work?
First off, as you typically use it with RAC (though it does work with single nodes, thanks Greg for the clarification) and requires 11gR2, it's not the easiest thing to set up in a test environment, so I'm going off white papers and presentations for the time being. Conceptually, it's a different approach to vendors like QlikView and Microsoft (with PowerPivot) who are using the local memory on users' PC, with Oracle instead using the aggregated memory of nodes in a RAC cluster. As such it's something an administrator would set up rather than users, though once its set up it should just take effect in the background, making queries run faster.
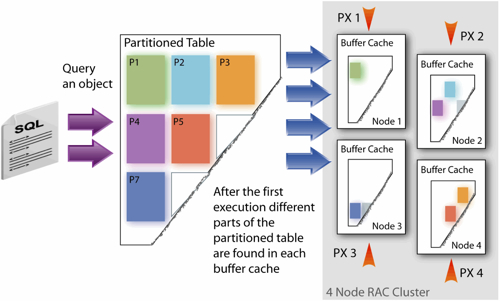
As the name suggests, In-Memory Parallel Query is based of the parallel execution feature in the database that divides up the task of scanning a large table into several processes that each scan a part of the table. It's typically used in conjunction with partitioning and servers with lots of CPUs, and prior to 11gR2, these parallel server processes (co-ordinated by the query co-ordinator, linked to your login session) would in most cases read the required data (broken into "granules") direct from disk bypassing the buffer cache using direct path I/O, so as not to age everything out with what would presumably be a large amount of incoming data. Only objects smaller than 2% of the size of the buffer cache for an individual database instance would get read into the buffer cache, as illustrated in this diagram from Maria Colgan & Thierry Cruanes's Open World Presentation, "Extreme Performance with Oracle Database 11g and In-Memory Parallel Execution", which shows traditional PQ working with a small partitioned table and a four-node RAC cluster. Note how individual partitions (objects) are going into each node's buffer cache.
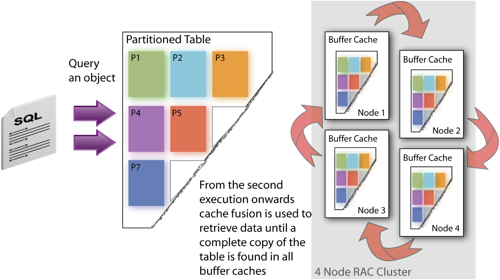
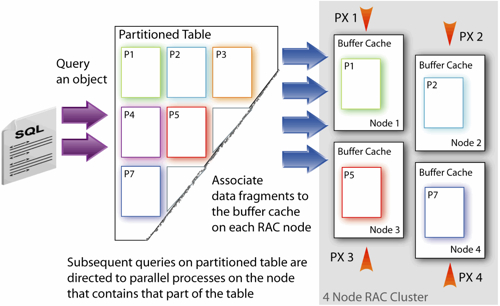
There's a new parameter in 11gR2 called PARALLEL_DEGREE_POLICY, which enables a bunch of new parallel query features introduced with this release. One thing it does is allows Oracle to decide whether, and how much degree of parallelism to use on a query, removing the need for you to set this manually per table, per query or whatever, with Oracle instead deciding based on the circumstances whether to use parallel query. Setting this parameter to AUTO also enables Parallel Statement Queuing, which gives Oracle the option to put a query on hold rather than have it either overwhelm the system, or more likely have its DOP scaled back so as not to do this. What this parameter also does when set to AUTO is enabled In-Memory Parallel Query.
With this feature enabled, Oracle will decide on a query-by-query basis whether to try and load the objects accessed by a statement into the aggregated buffer cache of your database server(s). There's a complex set of rules that Oracle uses to determine whether to cache these set of tables;
- the size of the objects (too small, it's not worth it; too big, it won't fit, but if they are big enough and fit within memory, they'll be considered)
- how often the objects are updated
- and so on
[Update 19th January : Updated article to remove comments about the feature being dependent on RAC. Thanks, Greg]