Agile Data Warehousing with Exadata and OBIEE: ETL Iteration
This is the fourth entry in my series on Agile Data Warehousing with Exadata and OBIEE. To see all the previous posts, check the introductory posting which I have updated with all the entries in the series.
In the last post, I describe what I call the Model-Driven iteration, where we take thin requirements from the end-user in the form of a user story and generate the access and performance layer, or our star schema, logically using the OBIEE semantic model. Our first several iterations will likely be Model-Driven as we work with the end user to fine-tune the content he or she wants to see on the OBIEE dashboards. As user stories are opened, completed and validated throughout the project, end users are prioritizing them for the development team to work on. Eventually, there will come a time when an end user opens a story that is difficult to model in the semantic layer. Processes to correct data quality issues are a good example, and despite having the power of Exadata at our disposal, we may find ourselves in a performance hole that even the Database Machine can't dig us out of. In these situations, we reflect on our overall solution and consider the maxim of Agile methodology: "refactoring", or "rework".
For Extreme BI, the main form of refactoring is ETL. The pessimist might say: "Well, now we have to do ETL development, what a waste of time all that RPD modeling was." But is that the case? First off... think about our users. They have been running dashboards for some time now with at least a portion of the content they need to get their jobs done. As the die-hard Agile proponent will tell you... some is better than none. But also... the process of doing the Model-Driven iteration puts our data modelers and our ETL developers in a favorable position. We've eliminated the exhaustive data modeling process, because we already have our logical model in the Business Model and Mapping layer (BMM).
{kind=link}
But we have more than that. We also have our source-to-target information documented in the semantic metadata layer. We can see that information using the Admin Tool, as depicted below, or we can also use the "Repository Documentation" option to generate some documented source-to-target mappings.
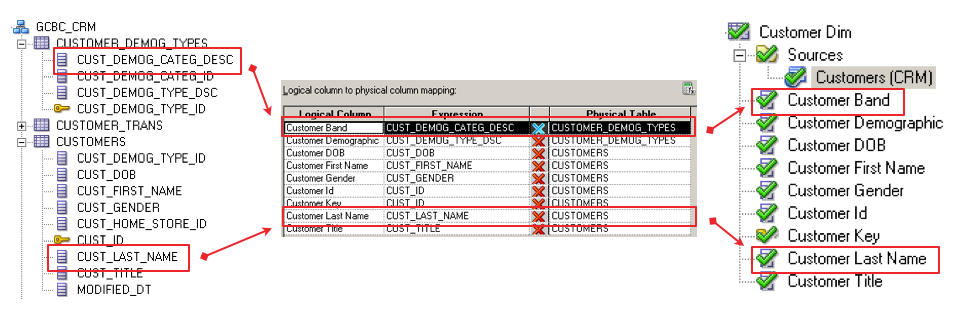{kind=link}
When embarking on ETL development, it's common to do SQL prototyping before starting the actual mappings to make sure we understand the particulars of granularity. However, we already have these SQL prototypes in the nqquery.log file... all we have to do is look at it. The combination of the source-to-target-mapping and the SQL prototypes provide all the artifacts necessary to get started with the ETL.
{kind=link}
When using ETL processing to "instantiate" our logical model into the physical world, we can't abandon our Agile imperatives: we must still deliver the new content, and corresponding rework, within a single iteration. So whether the end user is opening the user story because the data quality is abysmal, or because the performance is just not good enough, we must vow to deliver the ETL Iteration time-boxed, in exactly the same manner that we delivered the Model-Driven Iteration. So, if we imagine that our user opens a story about data quality in our Customer and Product dimensions, and we decide that all we have time for in this iteration are those two dimension tables, does it make sense for us to deliver those items in a vacuum? With the image below depicting the process flow for an entire subject area, can we deliver it piecemeal instead of all at once?
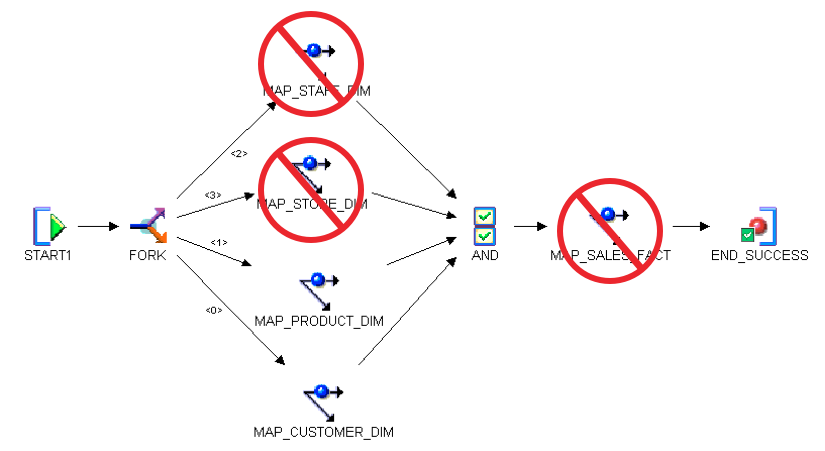{kind=link}
The answer, of course, is that we can. We'll develop the model and ETL exactly as we would if our goal was to plug the dimensions into a complete subject area. We use surrogate keys as the primary key for each dimension table, facilitating joining our dimension tables to completed fact tables. But we don't have completed fact tables at this point in our project... instead we have a series of transaction tables that work together to form the basis of a logical fact table. How can we use a dimension table with a surrogate key to join to our transactional "fact" table that doesn't yet have these surrogate keys?
We fake it. Along with surrogate keys, the long-standing best practice of dimension table delivery has been to include the source system natural key, as well as effective dates, in all our dimension tables. These attributes are usually included to facilitate slowly-changing dimension (SCD) processing, but we'll exploit them for our Agile piecemeal approach as well. So in our example below, we have a properly formed Customer dimension that we want to join to our logical fact table, as depicted below:
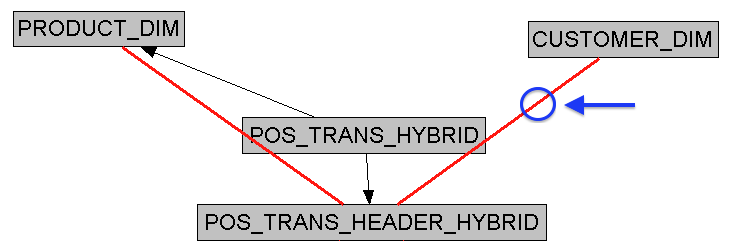{kind=link}
We start by creating aliases to our transactional "fact" tables (called POS_TRANS_HYBRID and POS_TRANS_HEADER_HYBRID in the example above), because we don't want to upset the logical table source (LTS) that we are already using for the pure transactional version of the logical fact table. We create a complex join between the customer source system natural key and transaction date in our hybrid alias, and the natural key and effective dates in the dimension table. We use the effective dates as well to make sure we grab the correct version of the customer entity in question in situations where we have enabled Type 2 SCD's (the usual standard) in our dimension table.
{kind=link}
This complex logic of using the natural key and effective dates is identical to the logic we would use in what Ralph Kimball calls the "surrogate pipeline": the ETL processing used to replace natural keys with surrogate keys when loading a proper fact table. Using Customer and Sales attributes in an analysis, we can see the actual SQL that's generated:
{kind=link}
We can view this hybrid approach as an intermediate step, but there is also nothing wrong with this as a long-term approach if the users are happy and Exadata makes our queries scream. If you think about it... a surrogate key is an easy was of representing the natural key of the table, which is the source system natural key plus the unique effective dates for the entity. A surrogate key makes this relationship much easier to envision, and certainly code using SQL, but when we are insulated from the ugliness of the join with Extreme Metadata, do we really care? If our end users ever open a story asking for rework of the fact table, we may consider manifesting that table physically as well. Once complete, we would need to create another LTS for the Customer dimension (using an alias to keep it separate from the table that joins to the transactional tables). This alias would be configured to join directly to the new Sales fact table across the surrogate key... exactly how we would expect a traditional data warehouse to be modeled in the BMM. The physical model will look nearly identical to our logical model, and the generated SQL will be less interesting:
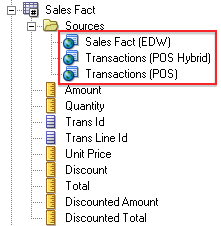{kind=link}
{kind=link}
Now that I've described the Model-Driven and ETL Iterations, it's time to discuss what I call the Combined Iteration, which is likely what most of the iterations will look like when the project has achieved some maturity. In Combined Iterations, we work on adding new or refactored RPD content alongside new or refactored ETL content in the same iteration. Now the project really makes sense to the end user. We allow the user community--those who are actually consuming the content--to dictate to the developers with user stories what they want the developers to work on in the next iteration. The users will constantly open new stories, some asking for new content, and others requesting modifications to existing content. All Agile methodologies put the burden of prioritizing user stories squarely on the shoulders of the user community. Why should IT dictate to the user community where priorities lie? If we have delivered fabulous content sourced with the Model-Driven paradigm, and Exadata provides the performance necessary to make this "real" content, then there is no reason for the implementors to dictate to the users the need to manifest that model physically with ETL when they haven't asked for it. If whole portions of our data warehouse are never implemented physically with ETL... do we care? The users are happy with what they have, and they think performance is fine... do we still force a "best practice" of a physical star schema on users who clearly don't want it?
So that's it for the Extreme BI methodology. At the onset of this series... I thought it would require five blog posts to make the case, but I was able to do it in four instead. So even when delivering blog posts, I can't help but rework as I go along. Long live Agile!