Agile Data Warehousing with Exadata and OBIEE: Model-Driven Iteration
After laying the groundwork with an introduction, and following up with a high-level description of the required puzzle pieces, it's time to get down to business and describe how Extreme BI works. At Rittman Mead, we have several projects delivering with this methodology right now, and more in the pipeline.
I'll gradually introduce the different types of generic iterations that we engage in, focusing on what I call the "model-driven" iteration for this post. Our first few iterations are always model-driven. We begin when a user opens a user story requesting new content. For any request for new content, we require that all the following elements are including in the story:
- A narrative about the data they are looking for, and how they want to see it. We are not looking for requirements documents here, but we are looking for the user to give a complete picture of what it is that they need.
- An indication of how they report on this content today. In a new data warehouse environment, this would include some sort of report that they are currently running against the source system, and in a perfect world, this would involve the SQL that is used to pull that report.
- An indication of data sets that are "nice to haves". This might include data that isn't available to them in the current paradigm of the report, or was simply too complicated to pull in that paradigm. After an initial inspection of these nice-to-haves and the complexity involved with including them in this story, the project manager may decide to pull these elements out and put them a separate user story. This, of course, depends on the Agile methodology used, and the individual implementation of that methodology.
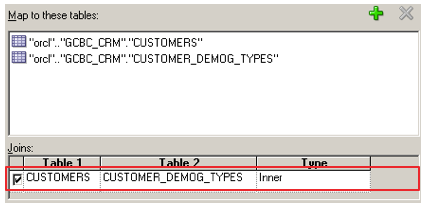
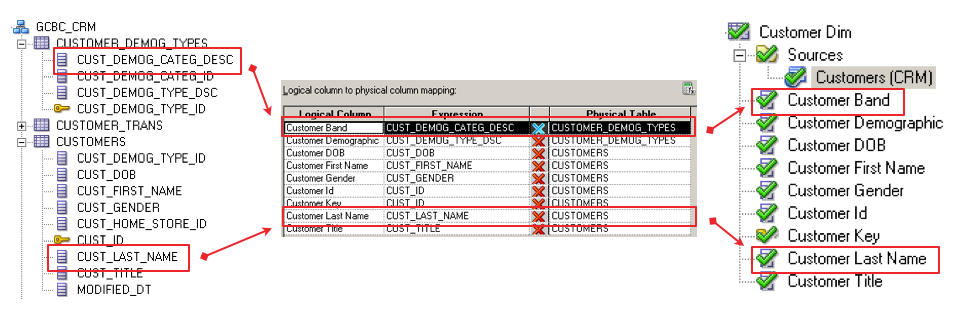
To take a simple example, we can see how a series of foundation layer tables developed in 3NF could be mapped to a logical dimension table as our Customer dimension:
{kind=link}
{kind=link}
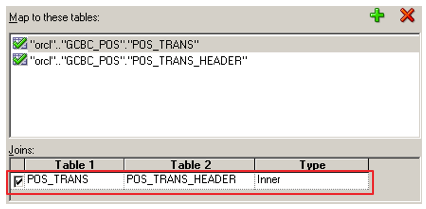
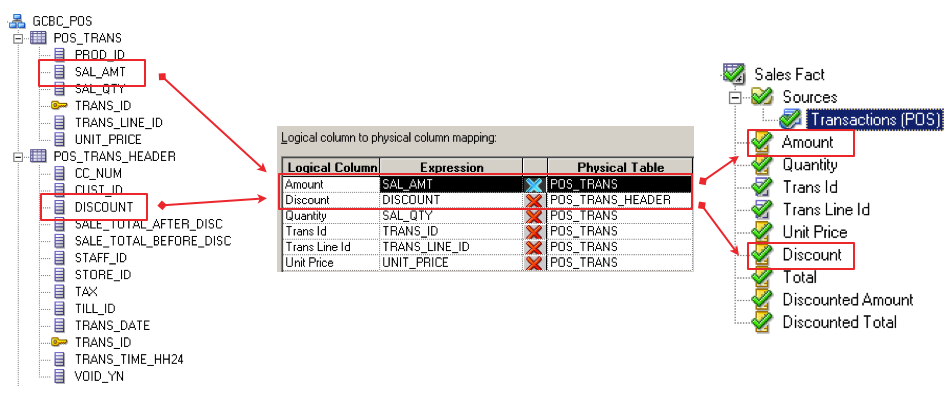
I rearranged the layout from the Admin Tool to provide an "ETL-friendly" view of the mapping. All the way to the right, we can see the logical, dimensional version of our Customer table, and how it maps back to the source tables. This mapping could be quite complicated, with perhaps dozens of tables. The important thing to keep in mind is that this complexity is hidden from not only the consumer of the reports, but also from the developers. We can generate a similar example of what our Sales fact table would look like:
{kind=link}
{kind=link}
Another way of making the same point is to look at the complex, transaction model:
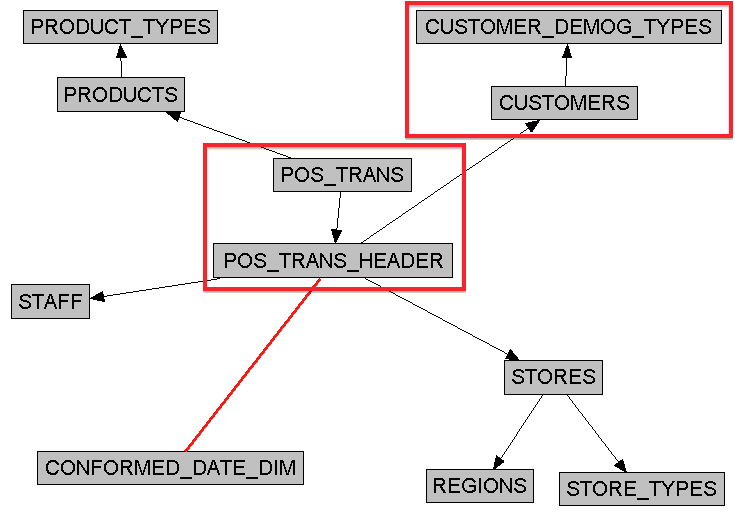{kind=link}
We can then compare this to the simplified, dimensional model:
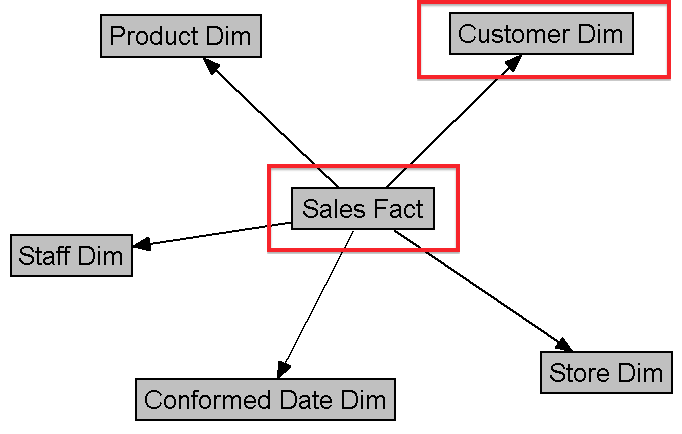{kind=link}
And finally, when we view the subject area during development of an analyses, all we see are facts and dimensions. The front-end developer can be blissfully ignorant that he or she is developing against a complex transactional schema, because all that is visible is the abstracted logical model:
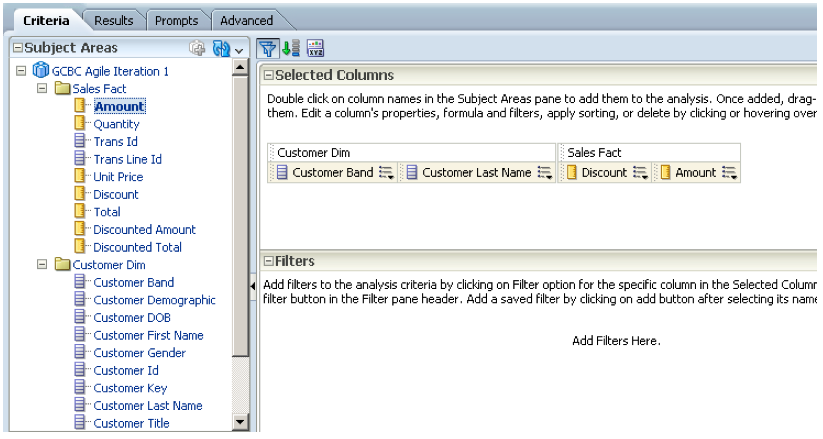{kind=link}
When mapping the BMM to complex 3NF schemas, the BI Server is very, very smart, and understands how to do more with less. Using the metadata capabilities of OBIEE is superior to other metadata products, or superior to a "roll-you-own metadata" approach using database views, because of the following:
- The generated SQL usually won't involve self-joins, even when tables exists in both the logical fact table, and the logical dimension table.
- The BI Server will only include tables that are required to facilitate the intelligent request, either because it has columns mapped to the attributes being requested, or because the table is a required reference table to bring disparate tables together. Any tables not required to facilitate the request will be excluded.
What we have at the end of the iteration is a completely abstracted view of our model: a complex, transactional, 3NF schema presented as a star schema. We are able to deliver portions of a subject area, which is important for time-boxed iterations. The Extreme Metadata of OBIEE 11g allows us to remove this complexity in a single iteration, but it's the performance of the Exadata Database Machine that allows us to build real analyses and dashboards and present it to the general user community.
In the next post, we'll examine the ETL Iteration, and explore how we can gradually manifest our logical business model into a physical model over time. As you will see, the ETL iteration is an optional one... it will be absolutely necessary in some environments, and completely superflous in others.