Automated RPD Builds with OBIEE
Introduction
Some time ago, I wrapped up a four-part series on using MDS XML as a basis for RPD development. Of course... you can (re-) read the blog posts to get up to speed on the concept... but I'll offer a quick refresher here. Using an XML-based "data-store" for our RPD allows us the ability to treat our RPD the way Java developers treat their class files. At the end of the day... when it's text, we can work with it. I paired this new(-ish) RPD storage format with the distributed version-control system (VCS) Git to highlight some truly radical development strategies. I speak on this approach quite often... and I always include a live demo of working on multiple branches of development at the same time, and using the power of Git at the end of it to merge the branches together to build a single, consistent RPD file, or an OBIEE RPD "release". The question I always get asked: why Git? Can we do this with Subversion? My answer: sort of. The Git-difference should be appreciated by RPD developers: it's all about metadata. Anyone who has set up a Subversion repository knows that branching was an afterthought. Our ability to "branch" relies on the manual creation of a directory called "branches" (right between "trunk" and "tags") that plays no special part in the Subversion architecture. But Git has branching functionality built way down in the metadata. When it comes time to merge two branches together, Git knows ahead of time whether a conflict will arise, and has already devised a strategy for pulling the closest ancestor between the two branches to do a three-way merge.What do we Get with Git?
Let's run through the spoils. First... developers work on feature, or "topic" branches to complete their work. This is an isolated, "virtual" copy of the repository branched of from the master branch at a certain point in time. Below, we can see an illustration of the "Git Flow" methodology, our preferred RPD multi-user development strategy at Rittman Mead: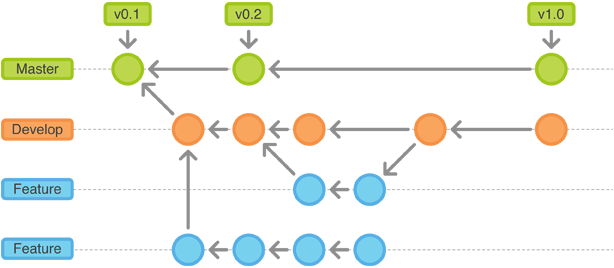
Developers no longer have to concern themselves with conflict resolution the way they have always had to when using MUDE. The merging is done after the fact... at the time when releases are assembled. And this brings me to the second--and most impactful--spoil: we are able to easily "cherry-pick" (yes... that is a technical term) features to go into our releases. For Agile methodologies that focus on delivering value to their users often... cherry-picking is a requirement, and it simply is not possible with either serialized, online development... or with OBIEE's built-in MUDE. As depicted in the Git Flow image above, we are able to cherry-pick the features we want to include in a particular release and merge them into our develop branch, and then prepare them for final delivery in the master branch, where we tag them as releases.
Is it Really So Radical?
Earlier, I described this methodology as "radical", which certainly requires context. For BI developers using OBIEE, Cognos, MicroStrategy, etc., this is indeed radical. But this is all old hat to Java developers, or Groovy developers, or Ruby on Rails developers, etc. For those folks, SDLC and methodologies like Git Flow are just how development is done. What is it about BI developers that make these concepts so foreign to us? Why are proper software development lifecycle (SDLC) strategies always an after-thought in the BI tools? All of them--Red Stack or otherwise--seem to "bolt-on" custom revisioning features after the fact instead of just integrating with proven solutions (Git, SVN, etc.) used by the rest of the world. When I speak to customers who are "uneasy" about stepping away from the OBIEE-specific MUDE approach, I reassure them that actually, branch-based SDLC is really the proven standard, while bespoke, siloed alternatives are the exception . Which gets us thinking... what else is the rest of the world doing that we aren't? The easy answer: automated builds.Should We Automate Our Builds?
The answer is yes. The development industry is abuzz right now with discussions about build automation and continuous integration, with oft-mentioned open-source projects such as Apache Maven, Jenkins CI, Grunt and Gradle. Although these open source projects are certainly on my radar (I'm currently testing Gradle for possible fit), an automated build process doesn't have to be near that fancy, and for most environments, could be produced with simple scripting using any interpretative language. To explain how an automated build would work for OBIEE metadata development, let's first explore the steps required if we were building a simple Java application. The process goes something like this:- Developers use Git (or other VCS) branches to track feature development, and those branches are used to cherry-pick combinations of features to package into a release.
- When the release has been assembled (or "merged" using Git terminology), then an automated process performs a build.
- The end result of our build process is typically an EAR file. As builds are configurable for different environments (QA, Production, etc.), our build process would be aware of this, and be capable of generating builds specific to multiple environments simultaneously.
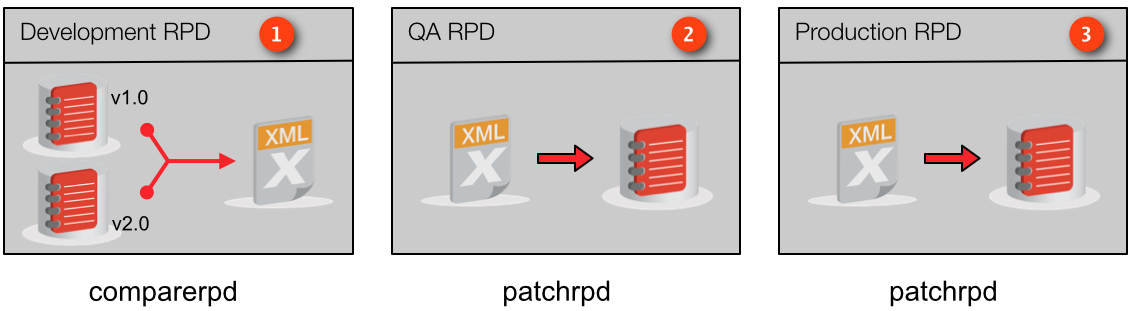
We'll explain this diagram in more detail as we go, because it's truly pivotal to understanding how our build process works. But in general... we version control our MDS XML repository for development, and use different versions of that MDS XML repository to generate patch files each time we build a release. That patch file is then applied to one or more target binary RPD files downstream in an automated fashion. Make sense?
To prepare ourselves for using MDS XML for automated builds, we have to start by generating binary RPD files for the different target environments we want to build for, in our case, QA and Production versions. We'll refer to these as our "baseline" RPD files: initially, they look identical to our development repository, but exist in binary format. These target binary RPD files will also be stored in Git to make it easy to pull back previous versions of our target RPDs, as well as to make it easy to deploy these files to any environment. We only have to generate our baselines once, so we could obviously do that manually using the Admin Tool, but we'll demonstrate the command-line approach here:

Once we have our binary QA and Production RPDs ready, we'll need to make any environment-specific configuration changes necessary for the different target environments. One obvious example of this kind of configuration is our connection pools. This is why we don't simply generate an RPD file from our MDS XML repository and use it for all the downstream environments: specifically, we want to be able to manage connection pool differences, but generically, we are really describing any environment-specific configurations, which is possible with controlled, automated builds. This is another step that only has to be performed once (or whenever our connection pool information needs updating, such as regular password updates) so it too can be performed manually using the Admin Tool.
Once our baselines are set, we can enable our build processes. We'll walk through the manual steps required to do a build, and after that, we'll have a quick look at Rittman Mead's automated build process.
Staging the Prior Version
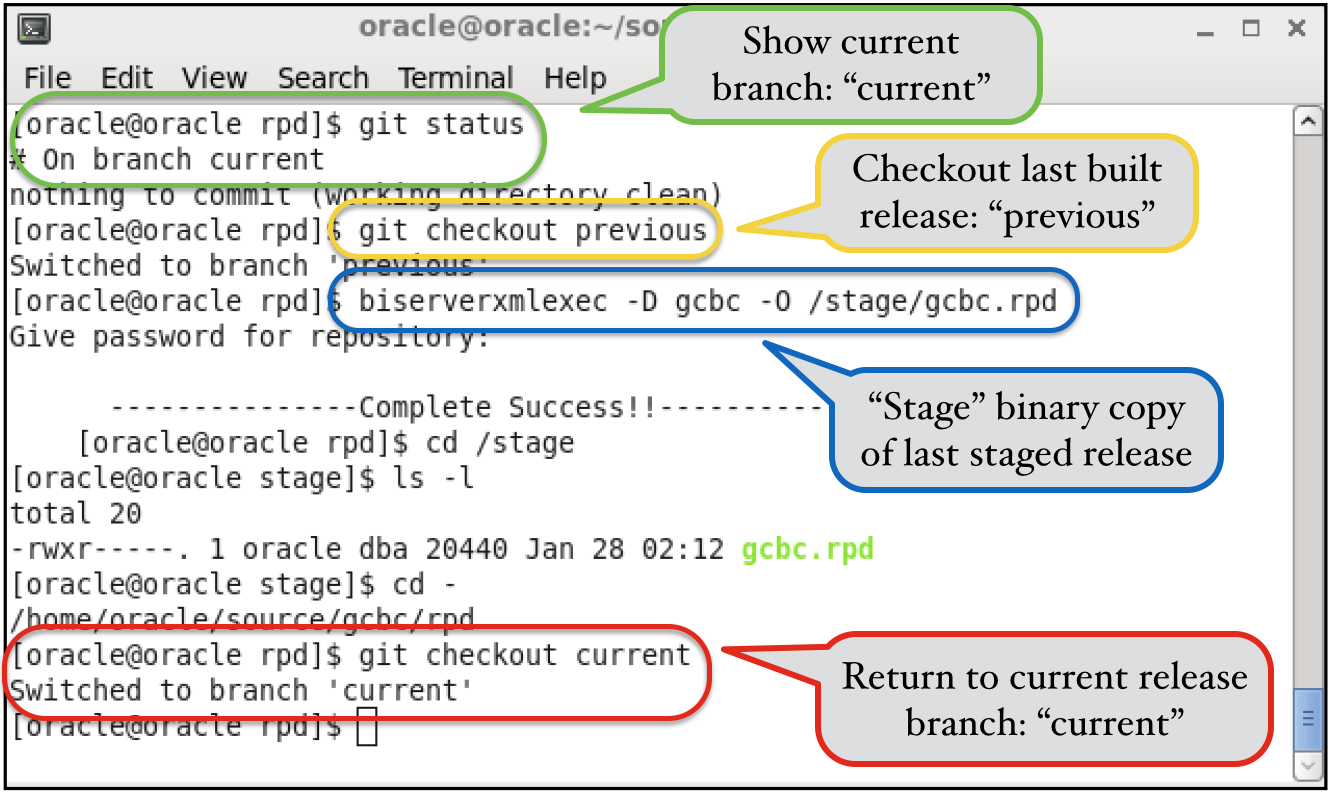
After we've completed development one or more new features, those branches will be merged into our develop branch (or the master branch if we aren't using Git Flow), giving us a consistent MDS XML repository that we are ready to push to our target environments. We'll need to compare our current MDS XML repository with the last development version that we produced so we can generate a patch file to drive our build process. There's a very important distinction to make here: we aren't going to compare our development repository directly against our QA or Production repositories, which is the approach I often see people recommending in blogs and other media. Hopefully, the reason will be clear in a moment.So where are we going to find the previous version of our MDS XML repository? Since we are using version control, we are able to checkout our previous build using either a branch or a tag. I'll demonstrate this using a branch, but it makes little difference from a process perspective, and most VCS (including Git) use the same command for either approach. To make this clear, I've created two branches: current and previous. The current branch is the one we've been diligently working on with new content... the previous branch is the branch we used to drive the build process last time around. So we need to "stage" a copy of the prior MDS XML repository, which we do by checking out the previous branch and extracting that repository to a location outside of our Git repository. Notice that we'll extract it as a binary RPD file; this is not a requirement, it's just easier to deal with a single file for this process:
Generating the Patch File
Now that we have staged our previous RPD file and returned to the current development branch, we are ready to proceed with generating a patch file. The patch file is generated by simply doing a comparison between our development MDS XML repository and the staged binary RPD file. The important thing to note about this approach: this patch file will not have any environment-specific information in it, such as connection pool configurations, etc. It only contains new development that's occurred in the development environment between the time of the last release and now: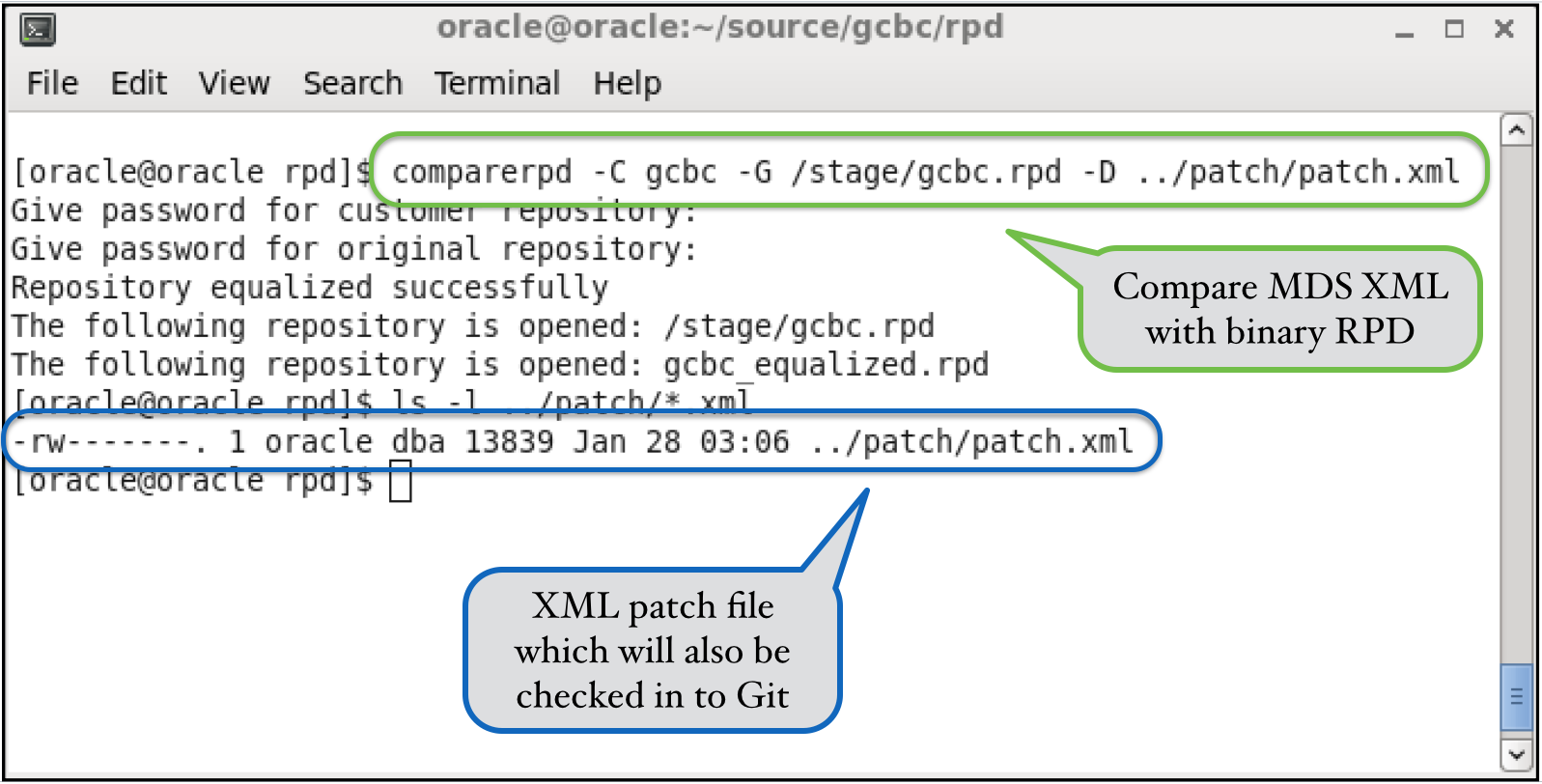
Applying Patch File to our Target(s)
With the staged, prior version of the binary RPD, and our patch file, we have all we need to apply the latest release to our target binary RPD files. In our case, we'll be applying the changes to both the QA and Production binary RPD files. Compared to everything we've done up until this point, this is really the easiest part. Below is a sample patchrpd process for our production RPD: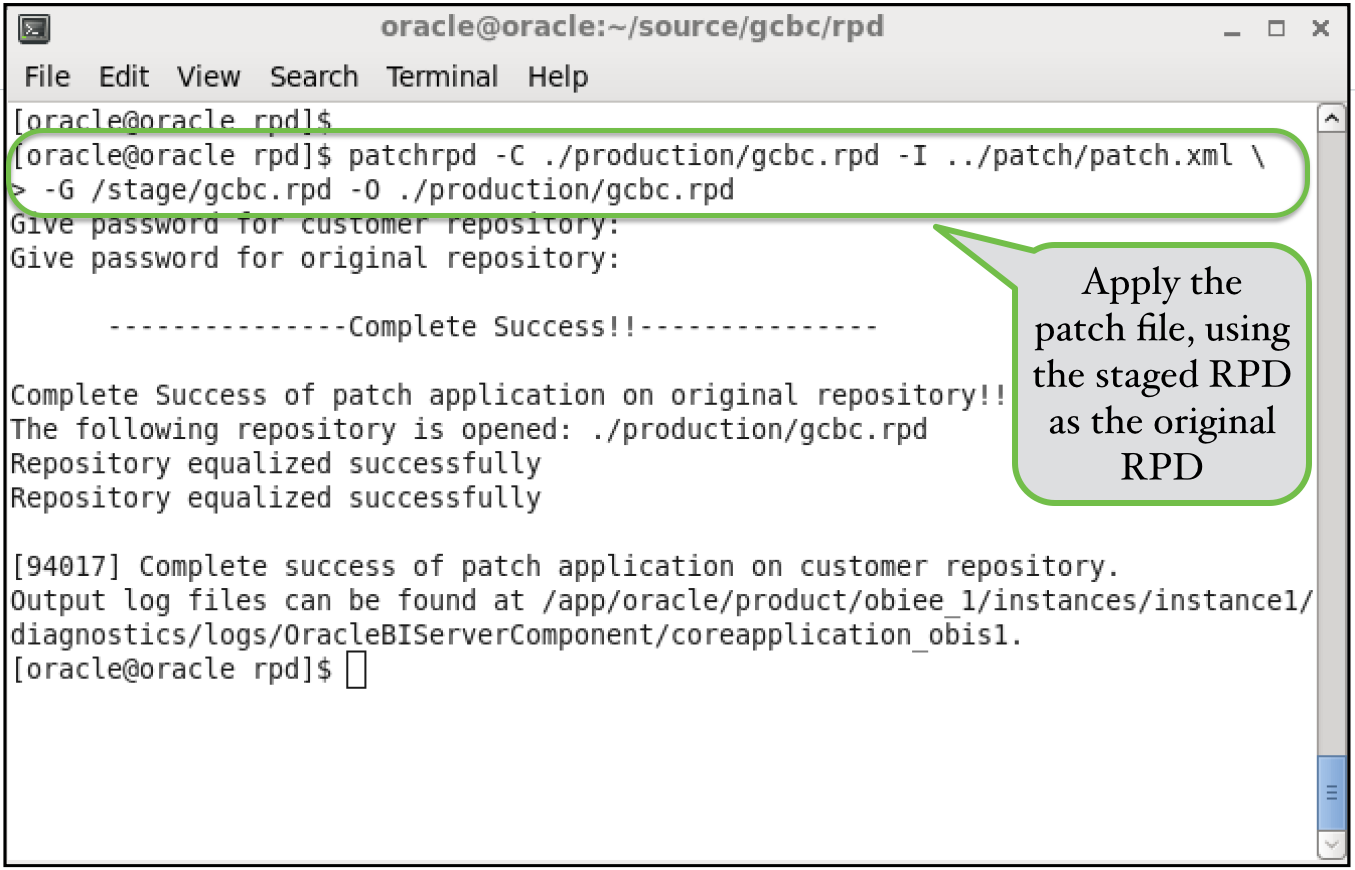
There are a lot more options we could incorporate into this process from a patching perspective. We cold use the -D option to introduce a decision file, which gives us the ability to highly customize this process. What we've demonstrated is a fairly simple option, but to be honest, in a controlled, SDLC approach, it's rare that we would ever need anything more than this simple process.
Automated Builds with the Rittman Mead Delivery Framework
As you can imagine, with all the brain-power floating around at Rittman Mead, we've packaged up a lot of automated processes over the years, and we have active development underway to refactor those processes into the Rittman Mead Delivery Framework. As these disparate pieces get incorporated into our Framework as a whole, we tend to rewrite them in either Groovy or Python... these languages have been adopted due to their strategic choice in Oracle products. I personally wrote our automated OBIEE build tool, and chose Groovy because of it's existing hooks into Gradle, Maven, Ant and all the rest. Also, the domain-specific language (DSL) capability of Groovy (used in both Grails and Gradle) is perfect for writing task-specific processes such as builds. The build process in our framework is driven by the buildConf.groovy config file, which is demonstrated below: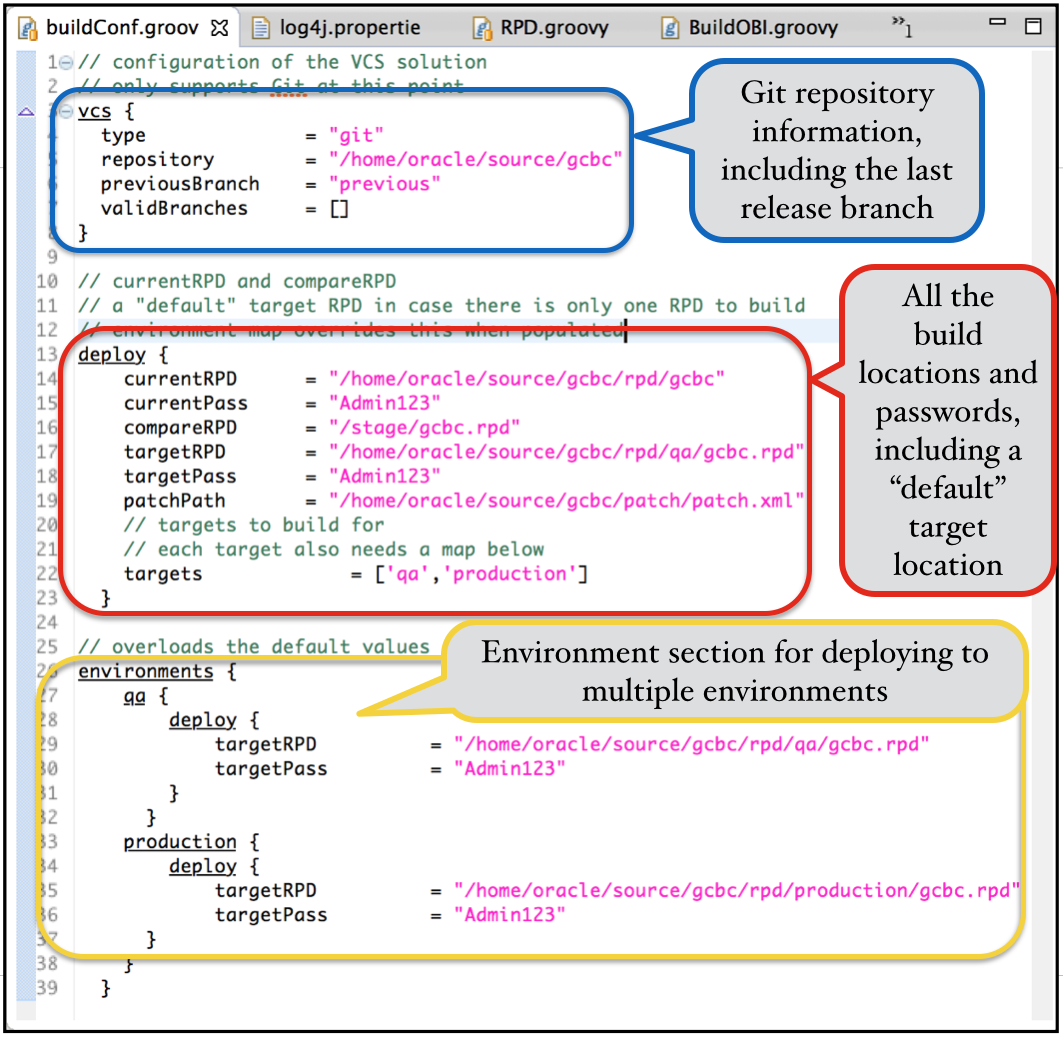
With Groovy, most things Java are pretty easy to incorporate, so I added Apache log4j functionality. Running the automated build process first in a logging mode of INFO, we see the following standard output:
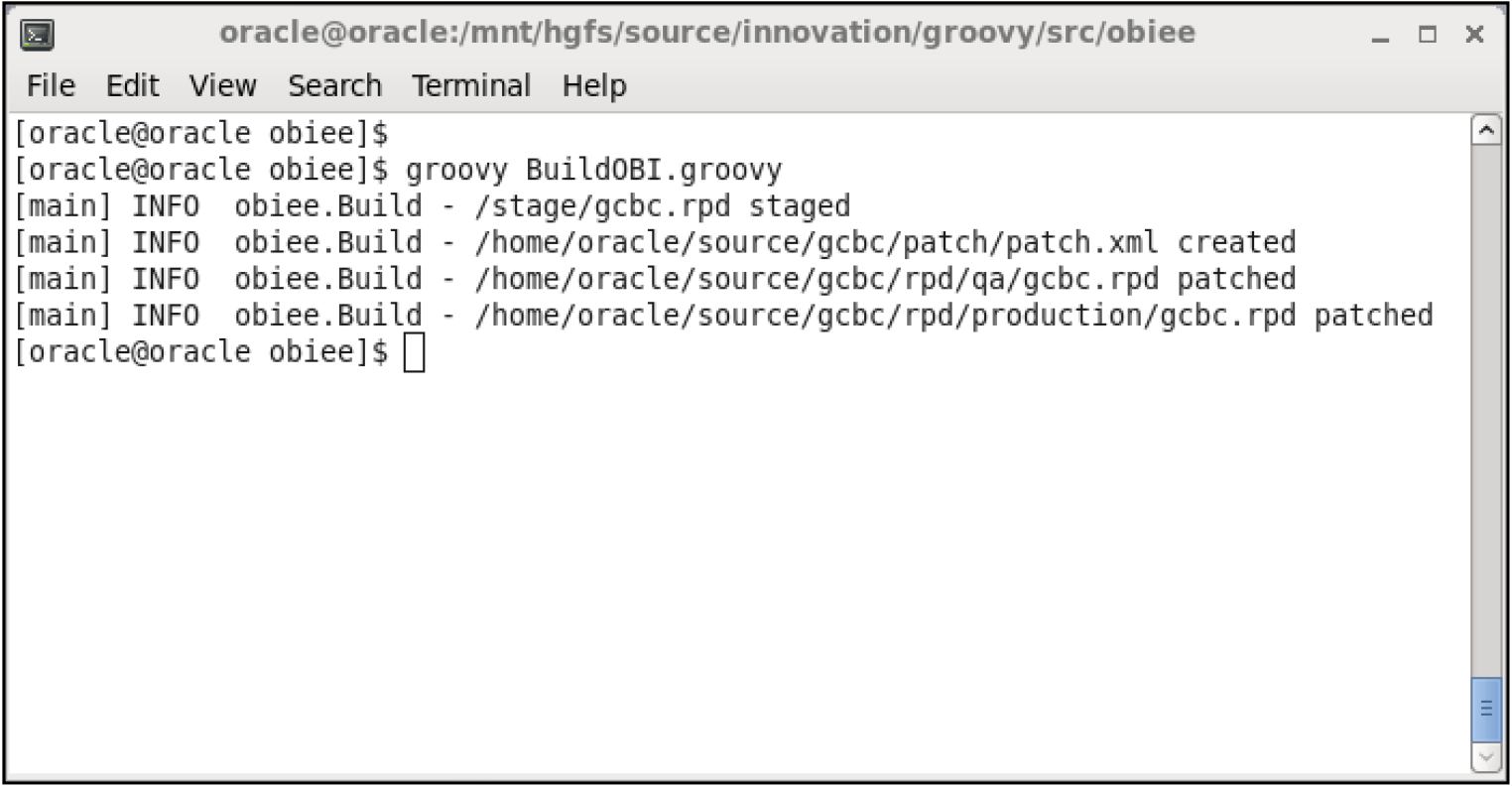
And now, in DEBUG mode:
[oracle@oracle obiee]$ groovy BuildOBI.groovy [main] DEBUG common.GitRepo - currentBranch: current [main] DEBUG common.Util - command: git checkout previous [main] DEBUG common.GitRepo - currentBranch: previous [main] DEBUG common.Util - command: biserverxmlexec -D /home/oracle/source/gcbc/rpd/gcbc -O /stage/gcbc.rpd -P Admin123 [main] DEBUG common.Util - command: git checkout current [main] DEBUG common.GitRepo - currentBranch: current [main] INFO obiee.Build - /stage/gcbc.rpd staged [main] DEBUG common.Util - command: comparerpd -P Admin123 -C /home/oracle/source/gcbc/rpd/gcbc -W Admin123 -G /stage/gcbc.rpd -D /home/oracle/source/gcbc/patch/patch.xml [main] INFO obiee.Build - /home/oracle/source/gcbc/patch/patch.xml created [main] DEBUG common.Util - command: patchrpd -C /home/oracle/source/gcbc/rpd/qa/gcbc.rpd -I /home/oracle/source/gcbc/patch/patch.xml -G /stage/gcbc.rpd -O /home/oracle/source/gcbc/rpd/qa/gcbc.rpd -P Admin123 -Q Admin123 [main] INFO obiee.Build - /home/oracle/source/gcbc/rpd/qa/gcbc.rpd patched [main] DEBUG common.Util - command: patchrpd -C /home/oracle/source/gcbc/rpd/production/gcbc.rpd -I /home/oracle/source/gcbc/patch/patch.xml -G /stage/gcbc.rpd -O /home/oracle/source/gcbc/rpd/production/gcbc.rpd -P Admin123 -Q Admin123 [main] INFO obiee.Build - /home/oracle/source/gcbc/rpd/production/gcbc.rpd patched [oracle@oracle obiee]$
The real power that Git brings (and frankly, other VCS's such as Subversion do as well) is the ability to configure commit hooks, such that scripts are executed whenever revisions are committed. You'll notice that the buildConf.groovy configuration file has a list option called validBranches. This allows us to configure the build to run only when the current branch is included in that list. We have that list unpopulated at the moment (meaning it's valid for all branches), but if we populated that list, then the build process would only run for certain branches. This would allow us to execute the build process as a commit process (either pre or post commit), but only have the build process run when being committed to particular branches, such as the develop branch or the master branch, when the code is prepared to be released.