Data Integration Tips: ODI 12c - Varchar2 (CHAR or BYTE)

Continuing with our Data Integration Tips series, here's one that applies to both Oracle Data Integrator 11g and 12c. This "tip" was actually discovered as a part of a larger issue involving GoldenGate, Oracle Datapump, and ODI. Maybe a future post will dive deeper into those challenges, but here I'm going to focus just on the ODI bit.
The Scenario
During our setup of GoldenGate and ODI, it was discovered that the source and target databases were set to use different character sets.
Source: WE8ISO8859P1
Target (DW): AL32UTF8
During my research, I found that the source is a single-byte character set and the target is multi-byte. What this means is that a special character, such as "Ǣ", for example, may take up more than one byte when stored in a column with a VARCHAR2 datatype (as described in the Oracle documentation - "Choosing a Character Set"). When attempting to load a column of datatype VARCHAR2(1) containing the text "Ǣ", the load would fail with an error, similar to the one below.
ORA-12899: value too large for column "COL_NAME" (actual: 2, maximum: 1)
The difference in character sets is clearly the issue, but how do we handle this when performing a load between the two databases? Reading through the Oracle doc referenced above, we can see that it all depends on the target database column length semantics. Specifically, for the attributes of VARCHAR2 datatype, we need to use character semantics in the target, "VARCHAR2(1 CHAR)", rather than byte semantics, "VARCHAR2(1 BYTE)". The former can handle multi-byte character sets simply by storing the characters as they are inserted. The latter will store each byte necessary for the character value individually. Looking back at the example, the character "Ǣ" inserted into a column using byte semantics (which is the default, in this case, when BYTE or CHAR is not specified) would require 2 bytes, thus causing the error.
Here's the Tip...
The overall solution is to modify any VARCHAR2 columns that may have special characters inserted to use character semantics in the target database. Quite often we cannot determine which columns may or may not contain certain data, requiring the modification of all columns to use character semantics. Using the database system tables, the alter table script to make the necessary changes to existing columns can be generated and executed. But what about new columns generated by ODI? Here we'll need to use the power of the Oracle Data Integrator metadata to create a new datatype.
In the ODI Topology, under the Physical Architecture accordion, the technologies that can be used as a data source or target are listed. Each technology, in turn, has a set of datatypes defined that may be used as Datastore Attributes when the technology is chosen in a Model.
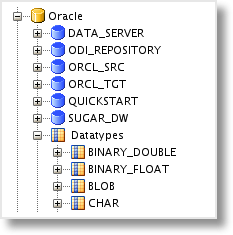
Further down in the list, you will find the VARCHAR2 datatype. Double-click the name to open the object. In the SQL Generation Code section we will find the syntax used when DDL is generated for a column of type VARCHAR2.

As you can see, the default is to omit the type of semantics used in the datatype syntax, which most likely means BYTE semantics are used, as this is typically the default in an Oracle database. This syntax can be modified to always produce character semantics by adding the CHAR keyword after the length substitution value.
VARCHAR(%L CHAR)
Before making the change to the "out of the box" VARCHAR2 datatype, you may want to think about how this datatype will be used on Oracle targets and sources. Any DDL generated by ODI will use this syntax when VARCHAR2 is selected for an attribute datatype. In some cases, this might be just fine as the ODI tool is only used for a single target data warehouse. But quite often, ODI is used in many different capacities, such as data migrations, data warehousing, etc. To handle both forms of semantics, the best approach is to duplicate the VARCHAR2 datatype and create a new version for the use of characters.
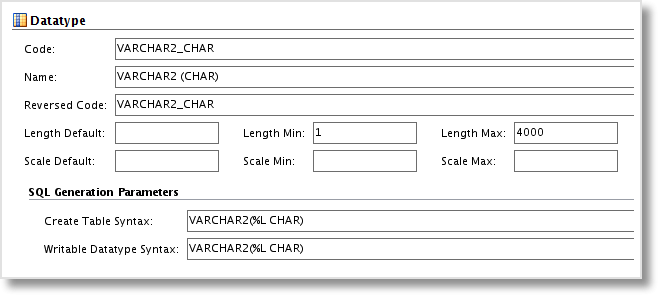
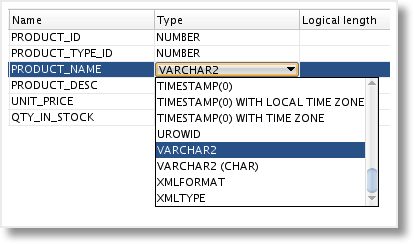
Now we can assign the datatype VARCHAR2 (CHAR) to any of our Datastore columns. I recommend the use of a Groovy script if changing Attributes in multiple Datastores.
Now when Generate DDL is executed on the Model, the Create Table step will have the appropriate semantics for the VARCHAR2 datatype.
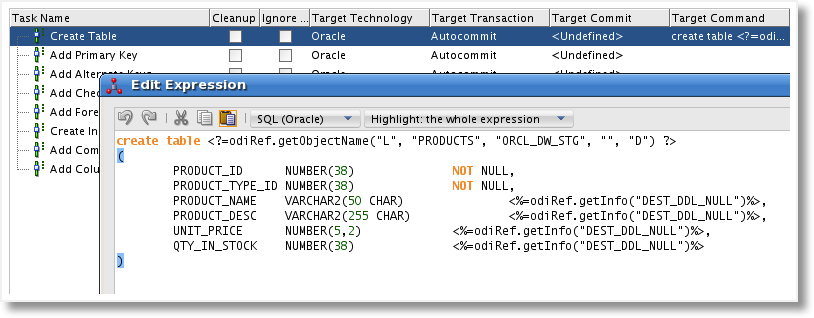
As you can see, the power of Oracle Data Integrator and the ability to modify and customize its metadata provided me with the solution in this particular situation. Look for more Data Integration Tips from Rittman Mead - coming soon!