Trickle-Feeding Log Files to HDFS using Apache Flume
In some previous articles on the blog I’ve analysed Apache webserver log files sitting on a Hadoop cluster using Hive, Pig and most recently, Apache Spark. In all cases the log files have already been sitting on the Hadoop cluster, SFTP’d to my local workstation and then uploaded to HDFS, the Hadoop distributed filesystem, using Hue, and the only way to add to them is to repeat the process and manually copy them across from our webserver. But what if I want these log files to be copied-across automatically, in a kind of “trickle-feed” process similar to how Oracle GoldenGate trickle-feeds database transactions to a data warehouse? Enter Apache Flume, a component within Hadoop and the Cloudera CDH4/5 distribution of Hadoop, which does exactly this.
Flume is an Apache project within the overall Hadoop ecosystem that provides a reliable, distributed mechanism for collecting aggregating and moving large amounts of log data. Similar to GoldenGate it has transaction collectors, mechanisms to reliably transmit data from source to target, and mechanisms to write those log events to a centralised data store, for example HDFS. It’s free and comes with Cloudera CDH, and coupled with something at the target end to then process and work with the incoming log entries, is a pretty powerful and flexible way to transmit log-type entries from (potentially) multiple source providers to a central Hadoop cluster.
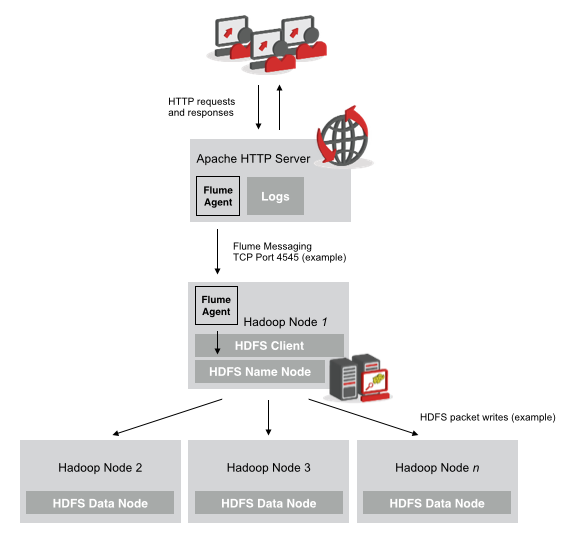
To take our example, we’ve got a webserver that’s generating our Apache CombinedLogFormat log entries as users generate activity on the website. We then set up Flume agents on the source webserver, and then the Hadoop client node that’s going to receive the log entries, which then writes the log entries to HDFS just like any other file activity. The Flume agent on the webserver source “tail”s the Apache access.log file copying across entries as they’re made (more or less), so that the target HDFS log file copies are kept up to date with individual log entries, not just whole log files as they’re closed off, with the diagram below showing the overall schematic:
Down at the Flume component level, Flume consists of agents, Java processes that sit on the source, target and any intermediate servers; channels, intermediate staging points that can persist log entries to disk, database or memory; and sinks, processes that take log transactions out of a channel and write them to disk. Flume is designed to be distributed and resilient, and won’t take the source down if the target Hadoop environment isn’t available; if this type of situation occurs, transactions will slowly fill-up the channel used by the source agent until such time as it runs out of space, and then further log transactions are lost until the target comes back up and the source agent’s channel regains some spare space. The diagram below, from the Cloudera blog about the latest generation of Flume (Flume NG, for “Next Generation”) shows the Flume product topology:

whilst the next diagram shows how Flume can collect and aggregate log entries from multiple servers, and then combine them into one log stream sent to a single target.

In our example, that’s all there is to it; in more complex examples, perhaps where the source is sending XML log entries, you’d need a downstream processor on the target platform to decode, deserialise or parse the incoming log files - Flume is just a transport mechanism and doesn’t do any transformation itself. You can also choose how the log entries are held by each of the agents’ channels; in the example we’re going to use, channel data is just held in-memory which is fast to run and setup, but you’d lose all of your data in the process if the server went down. Other, more production-level processes would persist the channel entries to file, or even a mySQL database.
For our setup we need to two agents, one on the source and one on the target server, each of which has its own configuration file. The source agent configuration file looks like this, with key entries called-out underneath it:
## SOURCE AGENT ## ## Local instalation: /home/ec2-user/apache-flume ## configuration file location: /home/ec2-user/apache-flume/conf ## bin file location: /home/ec2-user/apache-flume/bin ## START Agent: bin/flume-ng agent -c conf -f conf/flume-src-agent.conf -n source_agent # http://flume.apache.org/FlumeUserGuide.html#exec-source source_agent.sources = apache_server source_agent.sources.apache_server.type = exec source_agent.sources.apache_server.command = tail -f /etc/httpd/logs/access_log source_agent.sources.apache_server.batchSize = 1 source_agent.sources.apache_server.channels = memoryChannel source_agent.sources.apache_server.interceptors = itime ihost itype # http://flume.apache.org/FlumeUserGuide.html#timestamp-interceptor source_agent.sources.apache_server.interceptors.itime.type = timestamp # http://flume.apache.org/FlumeUserGuide.html#host-interceptor source_agent.sources.apache_server.interceptors.ihost.type = host source_agent.sources.apache_server.interceptors.ihost.useIP = false source_agent.sources.apache_server.interceptors.ihost.hostHeader = host # http://flume.apache.org/FlumeUserGuide.html#static-interceptor source_agent.sources.apache_server.interceptors.itype.type = static source_agent.sources.apache_server.interceptors.itype.key = log_type source_agent.sources.apache_server.interceptors.itype.value = apache_access_combined # http://flume.apache.org/FlumeUserGuide.html#memory-channel source_agent.channels = memoryChannel source_agent.channels.memoryChannel.type = memory source_agent.channels.memoryChannel.capacity = 100 ## Send to Flume Collector on Hadoop Node # http://flume.apache.org/FlumeUserGuide.html#avro-sink source_agent.sinks = avro_sink source_agent.sinks.avro_sink.type = avro source_agent.sinks.avro_sink.channel = memoryChannel source_agent.sinks.avro_sink.hostname = 81.155.163.172 source_agent.sinks.avro_sink.port = 4545
- Source is set to “apache_server”, i.e. an Apache HTTP server
- The capture mechanism is the Linux “tail” command
- Log entries are held by the channel mechanism in-memory, rather than to file or database
- Timestamp is used by the source collector to tell which entries are new
- The agent then sends the log entries to a corresponding Flume agent on the Hadoop Cluster, in this case an IP address that corresponds to my network’s external IP address, with Flume network traffic then NATted by my router to cdh4-node1.rittmandev.com, the client node in my CDH4.6 Hadoop cluster running on VMWare.
The target server in my Hadoop cluster then has a corresponding configuration file set up, looking like this:
## TARGET AGENT ##
## configuration file location: /etc/flume-ng/conf
## START Agent: flume-ng agent -c conf -f /etc/flume-ng/conf/flume-trg-agent.conf -n collector
#http://flume.apache.org/FlumeUserGuide.html#avro-source
collector.sources = AvroIn
collector.sources.AvroIn.type = avro
collector.sources.AvroIn.bind = 0.0.0.0
collector.sources.AvroIn.port = 4545
collector.sources.AvroIn.channels = mc1 mc2
## Channels ##
## Source writes to 2 channels, one for each sink
collector.channels = mc1 mc2
#http://flume.apache.org/FlumeUserGuide.html#memory-channel
collector.channels.mc1.type = memory
collector.channels.mc1.capacity = 100
collector.channels.mc2.type = memory
collector.channels.mc2.capacity = 100
## Sinks ##
collector.sinks = LocalOut HadoopOut
## Write copy to Local Filesystem
#http://flume.apache.org/FlumeUserGuide.html#file-roll-sink
collector.sinks.LocalOut.type = file_roll
collector.sinks.LocalOut.sink.directory = /var/log/flume-ng
collector.sinks.LocalOut.sink.rollInterval = 0
collector.sinks.LocalOut.channel = mc1
## Write to HDFS
#http://flume.apache.org/FlumeUserGuide.html#hdfs-sink
collector.sinks.HadoopOut.type = hdfs
collector.sinks.HadoopOut.channel = mc2
collector.sinks.HadoopOut.hdfs.path = /user/root/flume-channel/%{log_type}/%y%m%d
collector.sinks.HadoopOut.hdfs.fileType = DataStream
collector.sinks.HadoopOut.hdfs.writeFormat = Text
collector.sinks.HadoopOut.hdfs.rollSize = 0
collector.sinks.HadoopOut.hdfs.rollCount = 10000
collector.sinks.HadoopOut.hdfs.rollInterval = 600
Key entries in this log file are:
- Apache AVRO is the file format we’re using to transmit the data, and Flume is working on port 4545
- There’s two sink collector channels defined - “mc1” for writing file entries to the local server filesystem, and one to HDFS
- The maximum number of events (log entries) Flume will store in the various channels (log entry persistence stores) is 100, meaning that if the target platform goes down and more than 100 log transactions back-up, then further ones will get lost until we can clear the channel down. Of course this limit can be increased, assuming there’s memory or disk spare.
I then SSH into the target Hadoop node and start the Flume agent, like this:
[root@cdh4-node1 ~]# flume-ng agent -c conf -f /etc/flume-ng/conf/flume-trg-agent.conf -n collector Info: Including Hadoop libraries found via (/usr/bin/hadoop) for HDFS access Info: Excluding /usr/lib/hadoop/lib/slf4j-api-1.6.1.jar from class path ... 14/05/18 18:15:29 INFO hdfs.HDFSDataStream: Serializer = TEXT, UseRawLocalFileSystem = false 14/05/18 18:15:29 INFO hdfs.BucketWriter: Creating /user/root/flume-channel/apache_access_combined/18052014/FlumeData.1400433329254.tmp
and then repeat the step for the source webserver, like this:
[ec2-user@ip-10-35-143-131 apache-flume]$ sudo bin/flume-ng agent -c conf -f conf/flume-src-agent.conf -n source_agent Warning: JAVA_HOME is not set! + exec /usr/bin/java -Xmx20m -cp '/home/ec2-user/apache-flume/conf:/home/ec2-user/apache-flume/lib/*' -Djava.library.path= org.apache.flume.node.Application -f conf/flume-src-agent.conf -n source_agent
Finally, moving across to Hue I can see new log entries being written to the HDFS file system:

So there you go - simple transport of webserver log entries from a remote server to my Hadoop cluster, via Apache Flume - thanks again to Nelio Guimaraes from the RM team for setting the example up.