Oracle GoldenGate, MySQL and Flume
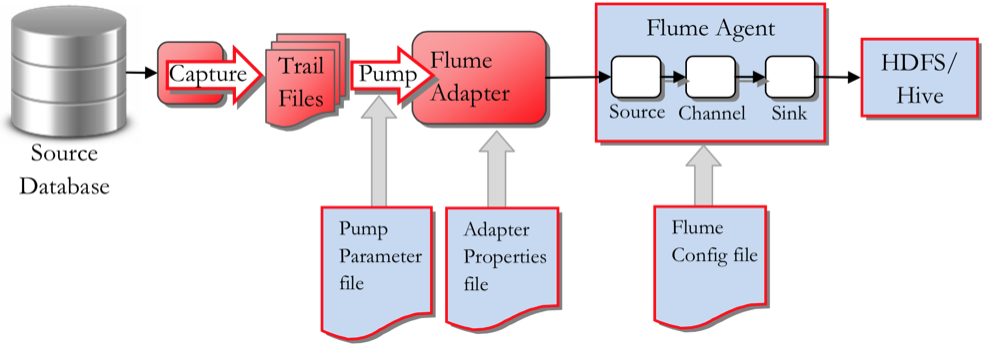
Back in September Mark blogged about Oracle GoldenGate (OGG) and HDFS . In this short followup post I'm going to look at configuring the OGG Big Data Adapter for Flume, to trickle feed blog posts and comments from our site to HDFS. If you haven't done so already, I strongly recommend you read through Mark's previous post, as it explains in detail how the OGG BD Adapter works. Just like Hive and HDFS, Flume isn’t a fully-supported target so we will use Oracle GoldenGate for Java Adapter user exits to achieve what we want.
What we need to do now is
- Configure our MySQL database to be fit for duty for GoldenGate.
- Install and configure Oracle GoldenGate for MySQL on our DB server
- Create a new OGG Extract and Trail files for the database tables we want to feed to Flume
- Configure a Flume Agent on our Cloudera cluster to 'sink' to HDFS
- Create and configure the OGG Java adapter for Flume
- Create External Tables in Hive to expose the HDFS files to SQL access
{kind=link}
Setting up the MySQL Database Source Capture
The MySQL database I will use for this example contains blog posts, comments etc from our website. We now want to use Oracle GoldenGate to capture new blog post and our readers' comments and feed this information in to the Hadoop cluster we have running in the Rittman Mead Labs, along with other feeds, such as Twitter and activity logs.
The database has to be configured to user binary logging and also we need to ensure that the socket file can be found in /tmp/mysql.socket. You can find the details for this in the documentation. Also we need to make sure that the tables we want to extract from are using the InnoDB engine and not the default MyISAM one. The engine can easily be changed by issuing
alter table wp_mysql.wp_posts engine=InnoDB;
Assuming we already have installed OGG for MySQL on /opt/oracle/OGG/ we can now go ahead and configure the Manager process and the Extract for our tables. The tables we are interested in are
wp_mysql.wp_posts wp_mysql.wp_comments wp_mysql.wp_users wp_mysql.wp_terms wp_mysql.wp_term_taxonomy
First configure the manager
-bash-4.1$ cat dirprm/mgr.prm PORT 7809 PURGEOLDEXTRACTS /opt/oracle/OGG/dirdat/*, USECHECKPOINTS
Now configure the Extract to capture changes made to the tables we are interested in
-bash-4.1$ cat dirprm/mysql.prm EXTRACT mysql SOURCEDB wp_mysql, USERID root, PASSWORD password discardfile /opt/oracle/OGG/dirrpt/FLUME.dsc, purge EXTTRAIL /opt/oracle/OGG/dirdat/et GETUPDATEBEFORES TRANLOGOPTIONS ALTLOGDEST /var/lib/mysql/localhost-bin.index TABLE wp_mysql.wp_comments; TABLE wp_mysql.wp_posts; TABLE wp_mysql.wp_users; TABLE wp_mysql.wp_terms; TABLE wp_mysql.wp_term_taxonomy;
We should now be able to create the extract and start the process, as with a normal extract.
ggsci>add extract mysql, tranlog, begin now ggsci>add exttrail ./dirdat/et, extract mysql ggsci>start extract mysql ggsci>info mysql ggsci>view report mysql
We will also have to generate metadata to describe the table structures in the MySQL database. This file will be used by the Flume adapter to map columns and data types to the Avro format.
-bash-4.1$ cat dirprm/defgen.prm
-- To generate trail source-definitions for GG v11.2 Adapters, use GG 11.2 defgen,
-- or use GG 12.1.x defgen with "format 11.2" definition format.
-- If using GG 12.1.x as a source for GG 11.2 adapters, also generate format 11.2 trails.
-- UserId logger, Password password
SOURCEDB wp_mysql, USERID root, PASSWORD password
DefsFile dirdef/wp.def
TABLE wp_mysql.wp_comments;
TABLE wp_mysql.wp_posts;
TABLE wp_mysql.wp_users;
TABLE wp_mysql.wp_terms;
TABLE wp_mysql.wp_term_taxonomy;
-bash-4.1$ ./defgen PARAMFILE dirprm/defgen.prm
***********************************************************************
Oracle GoldenGate Table Definition Generator for MySQL
Version 12.1.2.1.0 OGGCORE_12.1.2.1.0_PLATFORMS_140920.0203
...
***********************************************************************
** Running with the following parameters **
***********************************************************************
SOURCEDB wp_mysql, USERID root, PASSWORD ******
DefsFile dirdef/wp.def
TABLE wp_mysql.wp_comments;
Retrieving definition for wp_mysql.wp_comments.
TABLE wp_mysql.wp_posts;
Retrieving definition for wp_mysql.wp_posts.
TABLE wp_mysql.wp_users;
Retrieving definition for wp_mysql.wp_users.
TABLE wp_mysql.wp_terms;
Retrieving definition for wp_mysql.wp_terms.
TABLE wp_mysql.wp_term_taxonomy;
Retrieving definition for wp_mysql.wp_term_taxonomy.
Definitions generated for 5 tables in dirdef/wp.def.
Setting up the OGG Java Adapter for Flume
The OGG Java Adapter for Flume will use the EXTTRAIL created earlier as a source, pack the data up and feed to the cluster Flume Agent, using Avro and RPC. The Flume Adapter thus needs to know
- Where is the OGG EXTTRAIL to read from
- How to treat the incoming data and operations (e.g. Insert, Update, Delete)
- Where to send the Avro messages to
First we create a parameter file for the Flume Adapter
-bash-4.1$ cat dirprm/flume.prm EXTRACT flume SETENV ( GGS_USEREXIT_CONF = "dirprm/flume.props") CUSEREXIT libggjava_ue.so CUSEREXIT PASSTHRU INCLUDEUPDATEBEFORES GETUPDATEBEFORES NOCOMPRESSUPDATES SOURCEDEFS ./dirdef/wp.def DISCARDFILE ./dirrpt/flume.dsc, purge TABLE wp_mysql.wp_comments; TABLE wp_mysql.wp_posts; TABLE wp_mysql.wp_users; TABLE wp_mysql.wp_terms; TABLE wp_mysql.wp_term_taxonomy;
There are two things to note here
- The OGG Java Adapter User Exit is configured in a file called flume.props
- The source tables' structures are defined in wp.def
The flume.props file is a 'standard' User Exit config file
-bash-4.1$ cat dirprm/flume.props gg.handlerlist=ggflume gg.handler.ggflume.type=com.goldengate.delivery.handler.flume.FlumeHandler gg.handler.ggflume.host=bd5node1.rittmandev.com gg.handler.ggflume.port=4545 gg.handler.ggflume.rpcType=avro gg.handler.ggflume.delimiter=; gg.handler.ggflume.mode=tx gg.handler.ggflume.includeOpType=true # Indicates if the operation timestamp should be included as part of output in the delimited separated values # true - Operation timestamp will be included in the output # false - Operation timestamp will not be included in the output # Default :- true gg.handler.ggflume.includeOpTimestamp=true # Optional properties to use the transaction grouping functionality #gg.handler.ggflume.maxGroupSize=1000 #gg.handler.ggflume.minGroupSize=1000 ### native library config ### goldengate.userexit.nochkpt=TRUE goldengate.userexit.timestamp=utc goldengate.log.logname=cuserexit goldengate.log.level=INFO goldengate.log.tofile=true goldengate.userexit.writers=javawriter gg.report.time=30sec gg.classpath=AdapterExamples/big-data/flume/target/flume-lib/* javawriter.stats.full=TRUE javawriter.stats.display=TRUE javawriter.bootoptions=-Xmx32m -Xms32m -Djava.class.path=ggjava/ggjava.jar -Dlog4j.configuration=log4j.properties
Some points of interest here are
- The Flume agent we will send our data to is running on port 4545 on host bd5node1.rittmandev.com
- We want each record to be prefixed with I(nsert), U(pdated) or D(delete)
- We want each record to be postfixed with a timestamp of the transaction date
- The Java class com.goldengate.delivery.handler.flume.FlumeHandler will do the actual work. (The curios reader can view the code in /opt/oracle/OGG/AdapterExamples/big-data/flume/src/main/java/com/goldengate/delivery/handler/flume/FlumeHandler.java)
Before starting up the OGG Flume, let's first make sure that the Flume agent on bd5node1 is configure to receive our Avro message (Source) and also what to do with the data (Sink)
a1.channels = c1
a1.sources = r1
a1.sinks = k2
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = bda5node1
a1.sources.r1.port = 4545
a1.sinks.k2.type = hdfs
a1.sinks.k2.channel = c1
a1.sinks.k2.hdfs.path = /user/flume/gg/%{SCHEMA_NAME}/%{TABLE_NAME}
a1.sinks.k2.hdfs.filePrefix = %{TABLE_NAME}_
a1.sinks.k2.hdfs.writeFormat=Writable
a1.sinks.k2.hdfs.rollInterval=0
a1.sinks.k2.hdfs.hdfs.rollSize=1048576
a1.sinks.k2.hdfs.rollCount=0
a1.sinks.k2.hdfs.batchSize=100
a1.sinks.k2.hdfs.fileType=DataStream
Here we note that
- The agent's source (inbound data stream) is to run on port 4545 and to use avro
- The agent's sink will write to HDFS and store the files in /user/flume/gg/%{SCHEMA_NAME}/%{TABLE_NAME}
- The HDFS files will be rolled over every 1Mb (1048576 bytes)
We are now ready to head back to the webserver that runs the MySQL database and start the Flume extract, that will feed all committed MySQL transactions against our selected tables to the Flume Agent on the cluster, which in turn will write the data to HDFS
-bash-4.1$ export LD_LIBRARY_PATH=/usr/lib/jvm/jdk1.7.0_55/jre/lib/amd64/server
-bash-4.1$ export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_55/
-bash-4.1$ ./ggsci
ggsci>add extract flume, exttrailsource ./dirdat/et
ggsci>start flume
ggsci>info flume
EXTRACT FLUME Last Started 2015-03-29 17:51 Status RUNNING
Checkpoint Lag 00:00:00 (updated 00:00:06 ago)
Process ID 24331
Log Read Checkpoint File /opt/oracle/OGG/dirdat/et000008
2015-03-29 17:51:45.000000 RBA 7742
If I now submit this blogpost I should see the results showing up our Hadoop cluster in the Rittman Mead Labs.
[oracle@bda5node1 ~]$ hadoop fs -ls /user/flume/gg/wp_mysql/wp_posts -rw-r--r-- 3 flume flume 3030 2015-03-30 16:40 /user/flume/gg/wp_mysql/wp_posts/wp_posts_.1427729981456
We can quickly create an externally organized table in Hive to view the results with SQL
hive> CREATE EXTERNAL TABLE wp_posts(
op string,
ID int,
post_author int,
post_date String,
post_date_gmt String,
post_content String,
post_title String,
post_excerpt String,
post_status String,
comment_status String,
ping_status String,
post_password String,
post_name String,
to_ping String,
pinged String,
post_modified String,
post_modified_gmt String,
post_content_filtered String,
post_parent int,
guid String,
menu_order int,
post_type String,
post_mime_type String,
comment_count int,
op_timestamp timestamp
)
COMMENT 'External table ontop of GG Flume sink, landed in hdfs'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ';'
STORED AS TEXTFILE
LOCATION '/user/flume/gg/wp_mysql/wp_posts/';
hive> select post_title from gg_flume.wp_posts where op='I' and id=22112;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1427647277272_0017, Tracking URL = http://bda5node1.rittmandev.com:8088/proxy/application_1427647277272_0017/
Kill Command = /opt/cloudera/parcels/CDH-5.3.0-1.cdh5.3.0.p0.30/lib/hadoop/bin/hadoop job -kill job_1427647277272_0017
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 0
2015-03-30 16:51:17,715 Stage-1 map = 0%, reduce = 0%
2015-03-30 16:51:32,363 Stage-1 map = 50%, reduce = 0%, Cumulative CPU 1.88 sec
2015-03-30 16:51:33,422 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.38 sec
MapReduce Total cumulative CPU time: 3 seconds 380 msec
Ended Job = job_1427647277272_0017
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Cumulative CPU: 3.38 sec HDFS Read: 3207 HDFS Write: 35 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 380 msec
OK
Oracle GoldenGate, MySQL and Flume
Time taken: 55.613 seconds, Fetched: 1 row(s)
Please leave a comment and you'll be contributing to an OGG Flume!