Oracle Data Integrator Enterprise Edition Advanced Big Data Option Part 1- Overview and 12.1.3.0.1 install

Oracle recently announced Oracle Data Integrator Enterprise Edition Advanced Big Data Options as part of the new 12.1.3.0.1 release of ODI. It includes various great new functionalities to work on an Hadoop ecosystem. Let's have a look at the new features and how to install it on Big Data Lite 4.1 Virtual Machine.
Note that some of these new features, for example Pig and Spark support and use of Oozie, requires the new ODI EE Advanced Big Data Option license on-top of base ODI EE.
Pig and Spark support
So far ODI12c allowed us to use Hive for any Hadoop-based transformation. With this new release, we can now use Pig and Spark as well. Depending on the use case, we can choose which technology will give better performance and switch from one to another with very few changes. That's the beauty of ODI – all you need is to do is create the logical dataflow in your mapping and choose your technology. There is no need to be a Pig Latin expert or a PySpark ninja, all of this will be generated for you! These two technologies are now available in the Topology, along with the Hadoop Data Server to define where lies the Data. You can also see some Loading Knowledge Modules for Pig and Spark.

Pig, as Mark wrote before, is a dataflow language. It makes it really appropriate with the new "flow paradigm" introduced in ODI 12c. The idea is to write a data pipeline in Pig Latin. That code will undercover create MapReduce jobs that will be executed.
Quoting Mark one more time, Spark is a cluster processing framework that can be used in different programming languages, the two most common being Python and Scala. It allows to do operation like filters, joins and aggregates. All of this can be done in-memory which can provides way better performance over MapReduce. The ODI team choose to use Python as a programming language for Spark so the Knowledge Modules will use PySpark.
New Hive Driver and LKMs
This release also brings significant improvements to the existing Hive technology. A new driver as been introduced under the name DataDirect Apache Hive JDBC Driver. It is actually the Weblogic Hive JDBC driver which aims at improving the performance and the stability.

New Knowledges Modules are introduced to benefit from this new driver and they are LKMs instead multi-connections IKMs as it use to be. Thanks to that, it can be combined with other LKMs into the same mapping which was not the case before.
Oozie Agent
Oozie is another Apache project and they define it as "a workflow scheduler system to manage Apache Hadoop jobs". We can create workflow of different jobs in the Hadoop stack, and then schedule it at a certain time or trigger it when data becomes available.
What Oozie does is similar to the role of the ODI agent, and it's now possible to use directly an existing Oozie engine instead of deploying a standalone agent on the hadoop cluster.
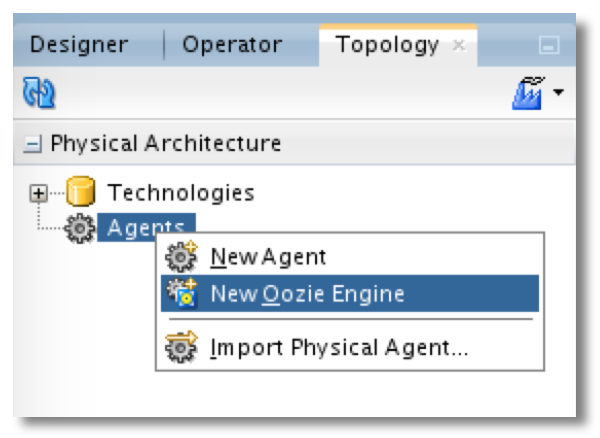
The Oozie engine will do what your ODI agent usually does – execution, scheduling, monitoring – but it is integrated in the Hadoop ecosystem. So we will be able to schedule and monitor our ODI jobs at the same place as all our other Hadoop jobs that we use outside of ODI. Oozie can also automatically retrieve the Hadoop logs. Also we lower the footprint because it doesn't requires to install an ODI-specific component on the cluster. However, according to the white paper (link below), it looks like Load Plans are not supported. So the idea would be to execute the Load Plans with a standalone or JEE agent that will delegate the execution of Big Data-related scenarios to the Oozie Engine.
HDFS support in file-related ODI Tools
Most of the ODI tools handling files can also do it on HDFS now. So you can delete, move, copy files and folders. You can also append files and transfer it to HDFS via FTP. It's even possible to detect when a file is created on HDFS. All you need to do is to indicate your Hadoop Logical Schema for source, target or both. In the following example I'm copying a file from the Unix filesystem to HDFS.
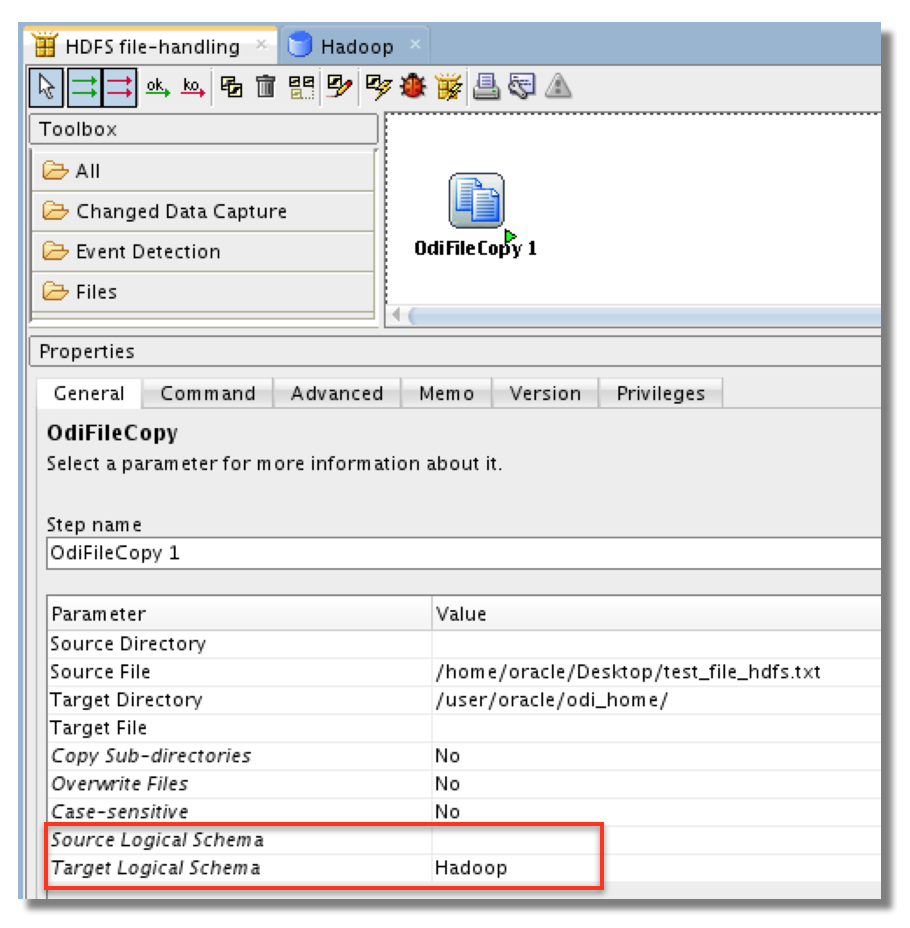
I think this is a huge step forward. If we want to use ODI 12c for our Hadoop data integration, it must be able to do everything end-to-end. The maintenance or administrative tasks such as archiving, deleting or copying should also be done using ODI. So far it was a bit tedious to created a shell script using hdfs dfs commands and then launch it using OdiOsCommand tool. Now we can directly use the file tools in a package or a procedure!
New mapping components : Jagged and Flatten
The two new components can be used in a Big Data context but also in your traditional data integration. The first one, Jagged, will pivot a set of key-value pairs into a columns with their values.
The Flatten components can be used with advanced files when you have nested attributes, like in JSON. Using a flatten component will generate more rows if needed to extract different values for a same attribute nested into another attribute.
You can see the detail of all the new features in the white paper "Advancing Big Data Integration" for ODI 12c.
How to install it?
This patch must be applied on top of an existing Oracle Data Integrator 12.1.3.0.0 installation. It is not a bundled patch and it's only related to Big Data Options so there is no point to install it if you don't need its functionalities. Also make sure you are licensed for ODIEE Advanced Big Data Option if you plan to use Spark or Pig technology/KMs or execute your jobs using the Oozie engine.
To showcase this, I used the excellent –and free! – Big Data Lite 4.1 VM which already has ODI 12.1.3 and all the Hadoop components we need. So this example will be on an Oracle Enterprise Linux environment.
The first step is to download it from the OTN or My Oracle Support. Also make sure you close ODI Studio and shut down the agents. Then the README recommends to update OPatch and check the OUI. So let's do that and also set some environment variables and unzip the ODI patch.
[oracle@bigdatalite ~]$ mkdir /home/oracle/bck [oracle@bigdatalite ~]$ ORACLE_HOME=/u01/ODI12c/ [oracle@bigdatalite ~]$ cd $ORACLE_HOME [oracle@bigdatalite ODI12c]$ unzip /home/oracle/Desktop/p6880880_132000_Generic.zip -d $ORACLE_HOME [oracle@bigdatalite ODI12c]$ OPatch/opatch lsinventory -jre /usr/java/latest/ [oracle@bigdatalite ODI12c]$ export PATH=$PATH:/u01/ODI12c/OPatch/ [oracle@bigdatalite ODI12c]$ unzip -d /home/oracle/bck/ /home/oracle/Desktop/p20042369_121300_Generic.zip [oracle@bigdatalite ODI12c]$ cd /home/oracle/bck/
This patch is actually composed of three piece. One of them, the second one, is only needed if you have an enterprise installation. If you have a standalone install, you can just skip it. Note that I always specify the JRE to be used by OPatch to be sure everything works fine.
[oracle@bigdatalite bck]$ unzip p20042369_121300_Generic.zip [oracle@bigdatalite ODI12c]$ cd 20042369/ [oracle@bigdatalite 20042369]$ opatch apply -jre /usr/java/latest/ [oracle@bigdatalite 20042369]$ cd /home/oracle/bck/ // ONLY FOR ENTERPRISE INSTALL //[oracle@bigdatalite bck]$ unzip p20674616_121300_Generic.zip //[oracle@bigdatalite bck]$ cd 20674616/ //[oracle@bigdatalite 20674616]$ opatch apply -jre /usr/java/latest/ //[oracle@bigdatalite 20674616]$ cd /home/oracle/bck/ [oracle@bigdatalite bck]$ unzip p20562777_121300_Generic.zip [oracle@bigdatalite bck]$ cd 20562777/ [oracle@bigdatalite 20562777]$ opatch apply -jre /usr/java/latest/
Now we need to run the upgrade assistant that will execute some scripts to upgrade our repositories. But in Big Data Lite, the tables of the repository have been compressed, so we first need to uncompress them and rebuild the invalid indexes as David Allan pointed it out on twitter. Here are the SQL queries that will create the DDL statement you need to run if you are also using Big Data Lite VM :
select 'alter table '||t.owner||'.'||t.table_name||' move nocompress;' q from all_tables t where owner = 'DEV_ODI_REPO' and table_name <> 'SNP_DATA'; select 'alter index '||owner||'.'||index_name||' rebuild tablespace '||tablespace_name ||';' from all_indexes where owner = 'DEV_ODI_REPO' and status = 'UNUSABLE';
Once it's done we can start the upgrade assistant :
[oracle@bigdatalite 20562777]$ cd /u01/ODI12c/oracle_common/upgrade/bin [oracle@bigdatalite bin]$ ./ua

The steps are quite straightforward so I'll leave it to you. Here I selected Schemas, but if you have a standalone agent you will have to run it again and select "Standalone System Component Configurations" to upgrade the domain as well.
Before opening ODI Studio we will clear the JDev cache so we are sure everything looks nice.
[oracle@bigdatalite bin]$ rm -rf /home/oracle/.odi/system12.1.3.0.0/
We can now open ODI Studio. Don't worry the version mentioned there and in the upgrade assistant is still 12.1.3.0.0 but if you can see the new features it has been installed properly.
The last step is to go in the topology and change the driver used for all the Hive Data Server. As all the new LKMs use the new weblogic driver, we need to define the url instead of the existing one. We simply select "DataDirect Apache Hive JDBC Driver" instead of the existing Apache driver.
And that's it, we can now enjoy all the new Big Data features in ODI 12c! A big thanks to David Allan and Denis Gray for their technical and licensing help. Stay tuned as I will soon publish a second blog post detailing some features.