Three Easy Ways to Stream Twitter Data into ElasticSearch
For the past few months a friend has been driving me crazy with all his praise for Splunk. He was going on about how easy it is to install, integrate different sources and build reports. I eventually started playing around to see if it could be used for a personal project I'm working on. In no time at all I understood what he was on about and I could see the value and ease of use of the product. Unfortunately the price of such a product means it is not a solution for everyone so I started looking around for alternatives and ElasticSearch caught my eye as a good option.
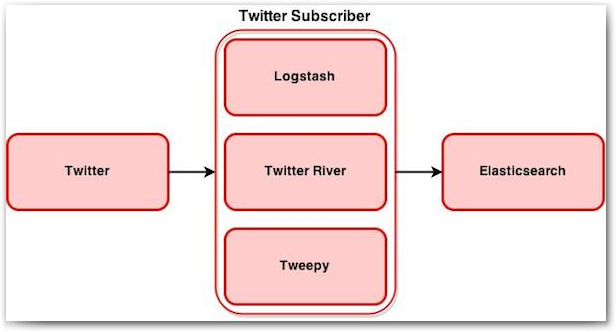
In this post we will focus on how we can stream Twitter data into ElasticSearch and explore the different options for doing so. Storing data in ElasticSearch is just the first step but you only gain real value when you start analysing this data. In the next post we will add sentiment analysis to our Twitter messages and see how we can analyse this data by building Kibana dashboards. But for now we will dig a bit deeper into the following three configuration options:
We will look at the installation and configuration of each of these and see how we can subscribe to twitter using the Twitter API. Data will then get processed, if required, and sent to Elasticsearch.
{kind=link}
Why Use Elasticsearch
Elasticsearch has the ability to store large quantities of semi-structured (JSON) data and provides the ability to quickly and easily query this data. This makes it a good option for storing Twitter data which is delivered as JSON and a perfect candidate for the project I'm working on.
Prerequisites
You will need a server to host all the required components. I used an AWS free tier (t2.micro) instance running Amazon Linux 64-bit. This post assumes you already have an elasticsearch cluster up and running and that you have a basic understanding of elasticsearch. There are some good blog posts, written by Robin Moffatt, which were very useful during the installation and configuration stages.
- Monitoring OBIEE with Elasticsearch, Logstash, and Kibana
- Analytics with Kibana and Elasticsearch through Hadoop – Part 1, Part 2 and Part 3
Twitter Stream API
In order to access the Twitter Streaming API, you need to register an application at http://apps.twitter.com. Once created, you should be redirected to your app’s page, where you can get the consumer key and consumer secret and create an access token under the “Keys and Access Tokens” tab. These values will be used as part of the configuration for all the sample configurations to follow.
The API allows two types of subscriptions. Either subscribe to specific keywords or to a user timeline (similar to what you see as a twitter user).
logstash
We'll start with logstash as this is probably the easiest one to configure and seems to be the recommended approach for integrating sources with elasticsearch in recent versions. At the time of writing this post, logstash only supported streaming based on keywords which meant it was not suitable for my needs but it's still a very useful option to cover.
logstash installation
To install logstash you need to download the correct archive based on the version of elasticsearch you are running.
curl -O https://download.elasticsearch.org/logstash/logstash/logstash-x.x.x.tar.gz
Extract the archived file and move the extracted folder to a location of your choice
tar zxf logstash-x.x.x.tar.gz mv logstash-x.x.x /usr/share/logstash/
logstash configuration
To configure logstash we need to provide input, output and filter elements. For our example we will only specify input (twitter) and output (elasticsearch) elements as we will be storing the full twitter message.
For a full list of logstash twitter input settings see the official documentation.
Using your favourite text editor, create a file called twitter_logstash.conf and copy the below text. Update the consumer_key, consumer_secret, oath_token and oath_token_secret values with the values from your Twitter Stream App created earlier.
input {
twitter {
# add your data
consumer_key => "CONSUMER_KEY_GOES_HERE"
consumer_secret => "CONSUMER_SECRET_GOES_HERE"
oauth_token => "ACCESS_TOKEN_GOES_HERE"
oauth_token_secret => "ACCESS_TOKEN_SECRET_GOES_HERE"
keywords => ["obiee","oracle"]
full_tweet => true
}
}
output {
elasticsearch_http {
host => "localhost"
index => "idx_ls"
index_type => "tweet_ls"
}
}
This configuration will receive all tweets tagged with obiee or oracle and store them to an index called idx_ls in elasticsearch.
To run logstash, execute the following command from the installed location
bin/logstash -f twitter_logstash.confIf you subscribed to active twitter tags you should see data within a few seconds. To confirm if your data is flowing you can navigate to http://server_ip:9200/_cat/indices?v which will show you a list of indices with some relevant information.
{kind=link}
With this easy configuration you can get Twitter data flowing in no time at all.
Twitter River Plugin
Next we will look at using the River Plugins to stream Twitter data. The only reason to use this approach over logstash is if you want to subscribe to a user timeline. Using this feature will show the same information as the Twitter application or viewing your timeline online.
Note!!Twitter River is not supported from ElasticSearch 2.0+ and should be avoided if possible. Thanks to David Pilato for highlighting this point. It is still useful to know of this option in the very rare case where it might be useful.
Twitter River Plugin installation
Before installing the plugin you need to determine which version is compatible with your version of elasticsearch. You can confirm this at https://github.com/elasticsearch/elasticsearch-river-twitter and selecting the correct one.
To install you need to use the elasticsearch plugin installation script. From the elasticsearch installation directory, execute:
bin/plugin -install elasticsearch/elasticsearch-river-twitter/x.x.x
Then restart your Elasticsearch service.
Twitter River Plugin configuration
To configure the twitter subscriber we will again create a .conf file with the necessary configuration elements. Create a new file called twitter_river.conf and copy the following text. As with logstash, update the required fields with the values from the twitter app created earlier.
{
"type": "twitter",
"twitter" : {
"oauth" : {
"consumer_key" : "CONSUMER_KEY_GOES_HERE",
"consumer_secret" : "CONSUMER_SECRET_GOES_HERE",
"access_token" : "ACCESS_TOKEN_GOES_HERE",
"access_token_secret" : "ACCESS_TOKEN_SECRET_GOES_HERE"
},
"filter" : {
"tracks" : ["obiee", "oracle"]
},
"raw" : true,
"geo_as_array" : true
},
"index": {
"index": "idx_rvr",
"type": "tweet_rvr",
"bulk_size": 100,
"flush_interval": "5s"
}
}
This configuration is identical to the logstash configuration and will receive the same tweets from twitter. To subscribe to a user timeline instead of keywords, replace the filter configuration element:
"filter" : {
"tracks" : ["obiee", "oracle"],
},
with a user type element
"type" : "user",
To start the plugin you need to execute the following from a terminal window.
curl -XPUT localhost:9200/_river/idx_rvr/_meta -d @twitter_river.conf
Depending on how active your subscribed tags are you should see data within a few seconds in elasticsearch. You can again navigate to http://server_ip:9200/_cat/indices?v to confirm if your data is flowing. Note this time that you should see two new rows, one index called _river and the other idx_rvr. idx_rvr is where your twitter data will be stored.
To stop the plugin (or change between keywords and user timeline), execute the following from a terminal window:
curl -XDELETE 'localhost:9200/_river/idx_rvr';
Tweepy
Finally we will look at the most flexible solution of them all. It is a bit more complicated to install and configure but, given what you gain, the small amount of extra time spent is well worth the effort. Once you have Tweepy working you will be able to write you own python code to manipulate the data as you see fit.
Tweepy installation
As Tweepy is a python package we will use pip to install the required packages. If you don't have pip installed. Execute one of the following, depending on your linux distribution.
yum -y install python-pipor
apt-get install python-pipNext we will install the Tweepy and elasticsearch packages
pip install tweepy
pip install elasticsearch
Tweepy configuration
Create a new file called twitter_tweepy.py and copy the following text to the file
import tweepy
import sys
import json
from textwrap import TextWrapper
from datetime import datetime
from elasticsearch import Elasticsearch
consumer_key="CONSUMER_KEY_GOES_HERE"
consumer_secret="CONSUMER_SECRET_GOES_HERE"
access_token="ACCESS_TOKEN_GOES_HERE"
access_token_secret="ACCESS_TOKEN_SECRET_GOES_HERE"
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
es = Elasticsearch()
class StreamListener(tweepy.StreamListener):
status_wrapper = TextWrapper(width=60, initial_indent=' ', subsequent_indent=' ')
def on_status(self, status):
try:
#print 'n%s %s' % (status.author.screen_name, status.created_at)
json_data = status._json
#print json_data['text']
es.create(index="idx_twp",
doc_type="twitter_twp",
body=json_data
)
except Exception, e:
print e
pass
streamer = tweepy.Stream(auth=auth, listener=StreamListener(), timeout=3000000000 )
#Fill with your own Keywords bellow
terms = ['obiee','oracle']
streamer.filter(None,terms)
#streamer.userstream(None)
As with the river plugin you can subscribe to the user timeline by changing the subscription type. To do this replace the last line in the script with
streamer.userstream(None)
To start the listener you need to execute the python file
python twitter_tweepy.py
Navigate to the elasticsearch index list again to ensure you are receiving data.
Conclusion
Getting Twitter data into Elasticsearch is actually pretty simple. Logstash is by far the easiest one to configure and if subscribing to keywords is your only requirement it should be the preferred solution. Now that we have the foundation in place, in the next post we will have a look at how we can enhance this data by adding sentiment analysis and how we can use this data to make decisions.