Analysing Social Media Data for the Lightyear Foundation - Part 1

Outside of my job at Rittman Mead, I'm fortunate enough to be involved with a project called the Lightyear Foundation. We are a charitable organisation which aims to promote the techniques and philosophies of science, working with children and teachers in the UK and Ghana. Particularly, we try to exemplify the fact that fundamental science principles can be demonstrated without the need for formal labs and expensive equipment. We believe that in increasing the accessibility to science, it will increase the prevalence of broadly applicable scientific skills such as critical thinking, communication of information, and the perception of failure.

As a charity, we have need for marketing and donations and are thus required to understand our donor base, just as any business might try to understand their customers. Which brings us neatly to this blog. It is common for businesses to analyse the efficacy of marketing campaigns with regards to revenue, which in the modern world can range from TV to Twitter. The collection and analysis of this data has then formed a multi-million dollar industry in and of itself. Unfortunately as a charity, we don't have multi-millions to spend on this analysis. Fortunately, we do have a search engine, a bit of ingenuity, and some elbow grease. Also, Rittman Mead was kind enough to donate a server to tinker with.
Looking for a Wheel
Before re-inventing the wheel, it seemed like a good idea to see if any wheels existed and indeed what they looked like. As you might expect, there are a great deal of analytics tools aimed at social media. The problem is that most of them require some sort of payment, and the vast majority of the free ones only allow analysis of a specific source. For example, Facebook provide an extensive insights platform for your page data, but this does not access anything from Twitter.
A notable exception is Cyfe, an absolutely fantastic platform that is free to use if you don't require historic analysis (queries are limited to the last 30 days). This is a very impressive application, and I will be revisiting this in a later blog. However, historic data is essential for holistic analysis rather than simply reporting, so I'm going to take a look at how difficult it would be to build something to allow that.
Exploring the Data
With any analytical project, exploring, collecting, and processing the data is the most important and time consuming part. To start with, a few data sources were identified as being useful for the investigation:
- Website
- YouTube
- MailChimp
This would give us information about our reach across the most important social media platforms as well as the website statistics and e-mail subscriptions. One notable omission from this blog is the donation system itself which is currently being changed. Each of the sources has an API for accessing various levels of information, with differing limitations. The first step was to try out each of the APIs and see what kind of data was retrievable.
Website Data
The easiest way to collect website data is to use Google Analytics, a free and excellent service that can be used to monitor and analyse traffic to our WordPress site. It works by embedding a small amount of JavaScript to each page, which then executes Google's tracking function, sending a variety of information about the session.
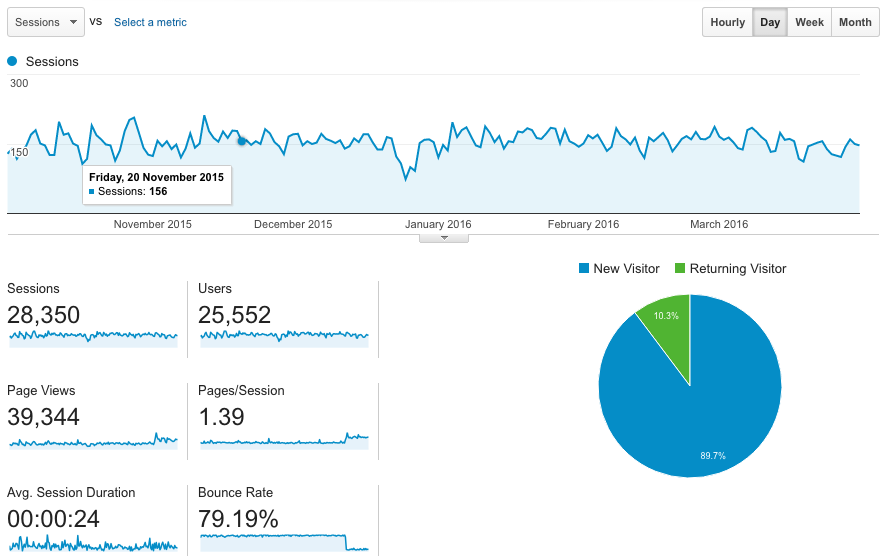
The above image is an excerpt of the kind of data provided by Google Analytics, showing the number of sessions activated on the website over a period of a few months. The platform has an incredibly detailed and vast store of data, including (among others):
- Session
- Clicks
- Geographic
- User Information (although this is often missing or incomplete)
- Referrals
- Network
- Browser
Naturally it also has an API, allowing online access in real time or offline access secured by a key on the server. For my initial testing, I setup an API key and wrote a python script to query the service:
>>> import lyf
>>> service = lyf.google_api('analytics', 'v3', ['https://www.googleapis.com/auth/analytics.readonly'])
>>> results = lyf.ga.query(service, '2016-07-21', '2016-07-24', 'ga:sessions', 'ga:date')
>>> for result in results:
print(result)
...
[u'20160721', u'6']
[u'20160722', u'7']
[u'20160723', u'26']
The authentication is performed using OAuth2 and is well documented. There is also a web interface for the API complete with handy auto-complete fields for each of the parameters.
While the platform is very fast and detailed, there is one limitation, which is that you can only choose up to 8 dimensions at a time for a query. For most use cases this is perfectly acceptable, but is worth noting.
Facebook provides their Graph API for querying data in this fashion as well as an explorer tool for testing. Authorisation can be granted and stored in the form of an API key. There is a permissions system of which the most important features are Manage Pages and Read Insights which give access to Facebook page information and reach data respectively. Some insights data is publicly available but appears to be limited to viewing a page's fanbase by country. Also, they store your data for two years, purging the rest. This means if you wish to store longer historic trends, you will need to siphon off the desired data and store it manually (we'll get to this later). Result sets are paginated, but feature a useful key-based system which allows easy retrieval of subsequent pages. As with Google, the performance of querying is very impressive, returning detailed data about 500 posts made over the last two years in under 30 seconds.
Once again, it was simple to produce the API HTTP requests using python's requests library. This library is able to automatically parse the returned JSON payload into a useful Python object. Below is an example of some simple queries run once the API was configured:
>>> results = lyf.fb_insights_query(['page_impressions'], 'day', since='2016-07-26')
>>> print(results['data'][0]['values'][0]['value'])
764
Twitter is a little trickier to work with. They have a public API which can be used to interface with Twitter quite extensively, but is not necessarily appropriate for analysis. Specifically, I was looking for metrics about reach and the number of impressions, similar to those obtained from Facebook's Insights API. These are available from Twitter's website, but only for a given time frame, as seen below.
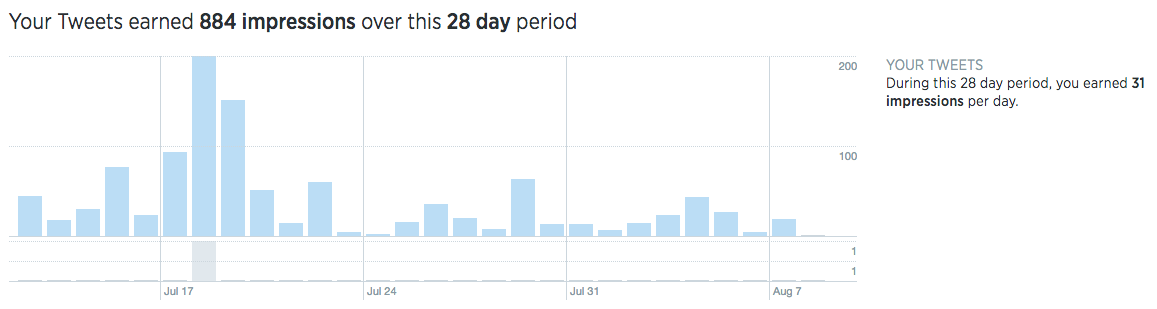
They do provide an analytical API for their Ads Service, but this does not appear to be publicly or freely available. Additionally, Gnip provides the official commercial outlet for analytical Twitter data.
Nevertheless, it was quite easy to get a Python integration set up for the public API by storing the consumer keys and access tokens for our Twitter account. Then I used Tweepy as a wrapper for Twitter's REST API. At the very least, follower and tweet count information is accessible, which can give some indication of popularity. Also, we'll be able to use this API to automate some tweet management if we need to at a later date.
YouTube
YouTube data is expectedly accessible using the same Google framework as before. This allows us to access publicly available YouTube data with only a small amount of additional set up. YouTube Analytics also has a very rich data platform similar to Google Analytics which can be seen below.
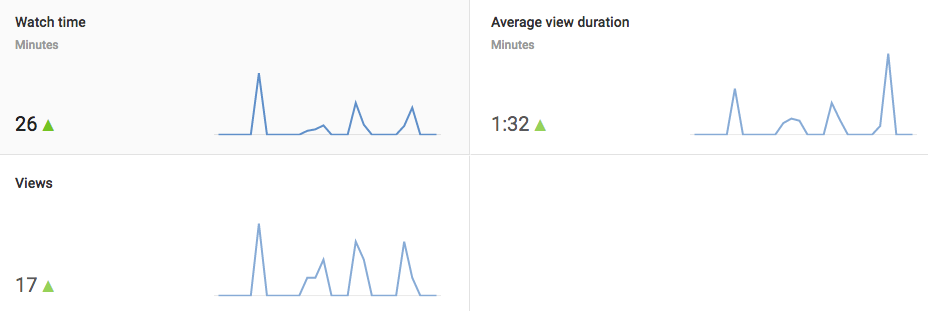
However, while it has an API, it cannot be used with a service account, the server-to-server setup I used earlier. So for now, we'll have to settle with collecting simple statistics (views and likes per video), but if we want the richer data set (watch time, demographics, audience retention) we will need to set up a live OAuth2 connection.
MailChimp
Last but not least, MailChimp also provides some analytics capability from within the site itself.
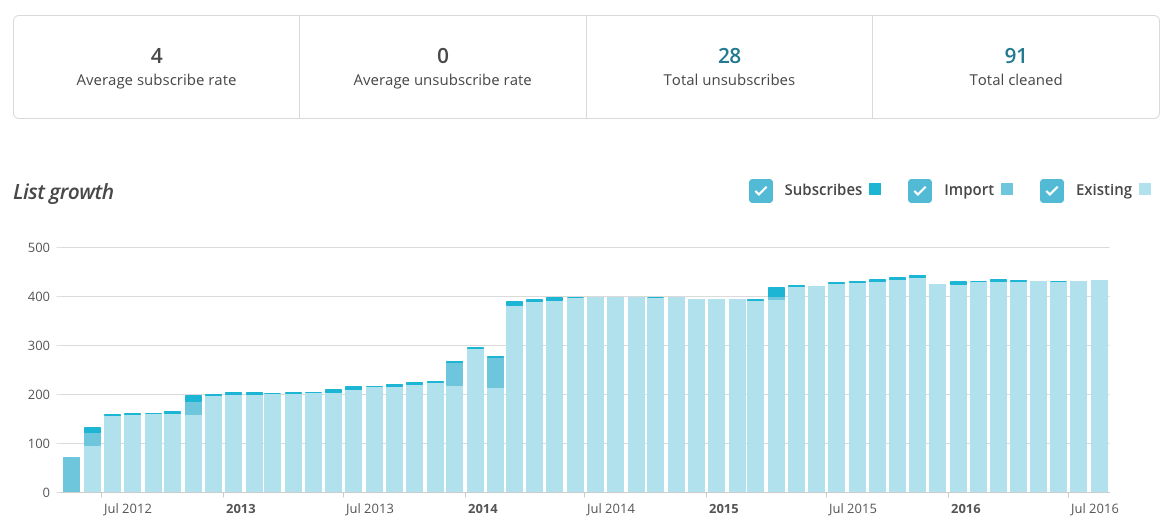
In addition, there is also a well documented API for looking at your subscription lists and campaigns. This can be simply queried using the requests library and supplying an API key.
Once again, as well as the ability to perform maintenance tasks, a decent amount of information is available:
- Click Rates
- Subscription Numbers
- Open Rates
- Geographical Information
- Recipients
- Devices
- Revenue
- Monthly History
Summary
That wraps up this first exploratory part, just dipping my toes into the various data streams out there. It's clear that there's a lot of data available but there still lies some complexity on tying it together for meaningful analysis. The next part of this blog series will look at trying to collect some of this data on a single platform so they can be queried together.
If you'd like to have a go at using the code from this blog, it's all on GitHub. Bear in mind that you will need to fill in a config.ini file from the sample, and configure it for authentication with your own social media accounts.
If you'd like to know more about how Rittman Mead can help your organisation make the most of this kind of data, please get in touch via the website.
Update: Check out part two of the blog here.