Data Processing and Enrichment in Spark Streaming with Python and Kafka

In my previous blog post I introduced Spark Streaming and how it can be used to process 'unbounded' datasets. The example I did was a very basic one - simple counts of inbound tweets and grouping by user. All very good for understanding the framework and not getting bogged down in detail, but ultimately not so useful.
We're going to stay with Twitter as our data source in this post, but we're going to consider a real-world requirement for processing Twitter data with low-latency. Spark Streaming will again be our processing engine, with future posts looking at other possibilities in this area.
Twitter has come a long way from its early days as a SMS-driven "microblogging" site. Nowadays it's used by millions of people to discuss technology, share food tips, and, of course, track the progress of tea-making. But it's also used for more nefarious purposes, including spam, and sharing of links to pirated material. The requirement we had for this proof of concept was to filter tweets for suspected copyright-infringing links in order that further action could be taken.
The environment I'm using is the same as before - Spark 2.0.2 running on Docker with Jupyter Notebooks to develop the code (and this article!). You can download the full notebook here.
The inbound tweets are coming from an Apache Kafka topic. Any matched tweets will be sent to another Kafka topic. The match criteria are:
- Not a retweet
- Contains at least one URL
- URL(s) are not on a whitelist (for example, we're not interested in links to spotify.com, or back to twitter.com)
- The Tweet text must match at least two from a predefined list of artists, albums, and tracks. This is necessary to avoid lots of false positives - think of how many music tracks there are out there, with names that are common in English usage ("yesterday" for example). So we must match at least two ("Yesterday" and "Beatles", or "Yesterday" and "Help!").
- Match terms will take into account common misspellings (Little Mix -> Litle Mix), hashtags (Little Mix -> #LittleMix), etc
We'll also use a separate Kafka topic for audit/debug purposes to inspect any non-matched tweets.
As well as matching the tweet against the above conditions, we will enrich the tweet message body to store the identified artist/album/track to support subsequent downstream processing.
The final part of the requirement is to keep track of the number of inbound tweets, the number of matched vs unmatched, and for those matched, which artists they were for. These counts need to be per batch and over a window of time too.
Getting Started - Prototyping the Processing Code
Before we get into the meat of the streaming code, let's take a step back and look at what we're wanting the code to achieve. From the previous examples we know we can connect to a Kafka topic, pull in tweets, parse them for given fields, and do windowed counts. So far, so easy (or at least, already figured out!). Let's take a look at nub of the requirement here - the text matching.
If we peruse the BBC Radio 1 Charts we can see the popular albums and artists of the moment (Grant me a little nostalgia here; in my day people 'pirated' music from the Radio 1 chart show onto C90 cassettes, trying to get it without the DJ talking over the start and end. Nowadays it's done on a somewhat more technologically advanced basis). Currently it's "Little Mix" with the album "Glory Days". A quick Wikipedia or Amazon search gives us the track listing too:
1. Shout Out to My Ex
2. Touch
3. F.U.
4. Oops - Little Mix feat. Charlie Puth
5. You Gotta Not
6. Down & Dirty
7. Power
8. Your Love
9. Nobody Like You
10. No More Sad Songs
11. Private Show
12. Nothing Else Matters
13. Beep Beep
14. Freak
15. Touch
A quick twitter search for the first track title gives us this tweet - I have no idea if it's legit or not, but it serves as an example for our matching code requirements:
DOWNLOAD MP3: Little Mix – Shout Out To My Ex (CDQ) Track https://t.co/C30c4Fel4u pic.twitter.com/wJjyG4cdjE
— Ngvibes Media (@ngvibes_com) November 3, 2016
Using the Twitter developer API I can retrieve the JSON for this tweet directly. I'm using the excellent Paw tool to do this.
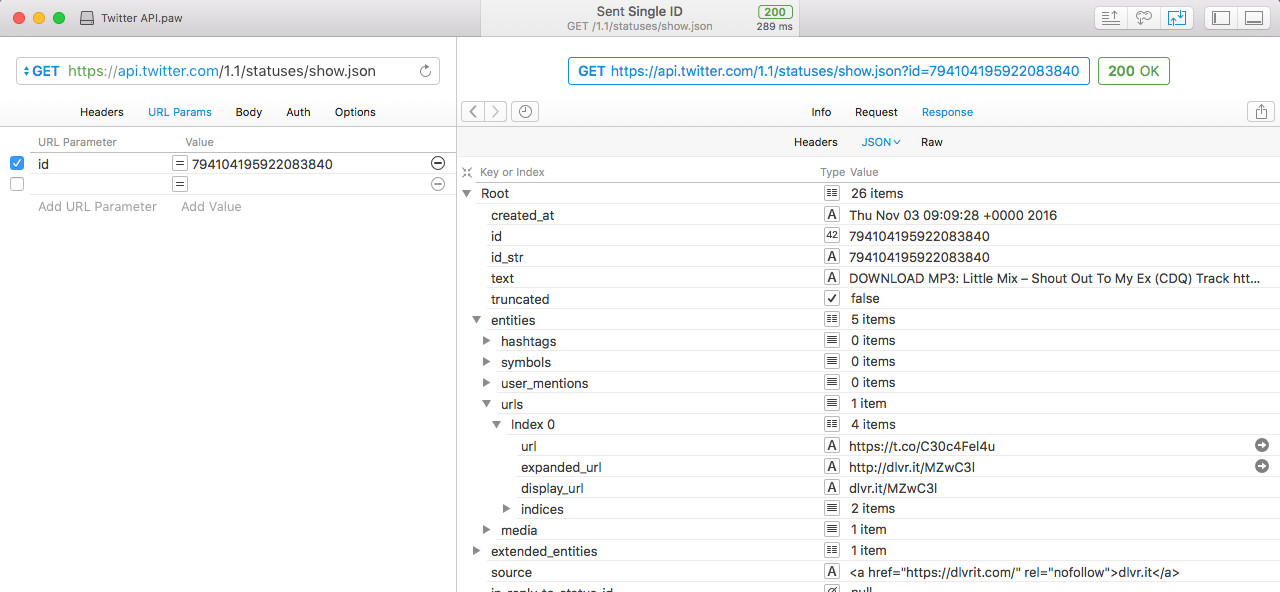
From this we can get the text element:
"text": "DOWNLOAD MP3: Little Mix \u2013 Shout Out To My Ex (CDQ) Track https:\/\/t.co\/C30c4Fel4u https:\/\/t.co\/wJjyG4cdjE",
The obvious approach would be to have a list of match terms, something like:
match_text=("Little Mix","Glory Days","Shout Out to My Ex","Touch","F.U.")
But - we need to make sure we've matched two of the three types of metadata (artist/album/track), so we need to know which it is that we've matched in the text. We also need to handle variations in text for a given match (such as misspellings etc).
What I came up with was this:
filters=[]
filters.append({"tag":"album","value": "Glory Days","match":["Glory Days","GloryDays"]})
filters.append({"tag":"artist","value": "Little Mix","match":["Little Mix","LittleMix","Litel Mixx"]})
filters.append({"tag":"track","value": "Shout Out To My Ex","match":["Shout Out To My Ex","Shout Out To My X","ShoutOutToMyEx","ShoutOutToMyX"]})
filters.append({"tag":"track","value": "F.U.","match":["F.U","F.U.","FU","F U"]})
filters.append({"tag":"track","value": "Touch","match":["Touch"]})
filters.append({"tag":"track","value": "Oops","match":["Oops"]})
def test_matching(test_string):
print 'Input: %s' % test_string
for f in filters:
for a in f['match']:
if a.lower() in test_string.lower():
print '\tTag: %s / Value: %s\n\t\t(Match string %s)' % (f['tag'],f['value'],a)
We could then take the test string from above and test it:
test_matching('DOWNLOAD MP3: Little Mix \u2013 Shout Out To My Ex (CDQ) Track https:\/\/t.co\/C30c4Fel4u https:\/\/t.co\/wJjyG4cdjE')
Input: DOWNLOAD MP3: Little Mix \u2013 Shout Out To My Ex (CDQ) Track https:\/\/t.co\/C30c4Fel4u https:\/\/t.co\/wJjyG4cdjE
Tag: artist / Value: Little Mix
(Match string Little Mix)
Tag: track / Value: Shout Out To My Ex
(Match string Shout Out To My Ex)
as well as making sure that variations in naming were also correctly picked up and tagged:
test_matching('DOWNLOAD MP3: Litel Mixx #GloryDays https:\/\/t.co\/wJjyG4cdjE')
Input: DOWNLOAD MP3: Litel Mixx #GloryDays https:\/\/t.co\/wJjyG4cdjE
Tag: album / Value: Glory Days
(Match string GloryDays)
Tag: artist / Value: Little Mix
(Match string Litel Mixx)
Additional Processing
With the text matching figured out, we also needed to address the other requirements:
- Not a retweet
- Contains at least one URL
- URL(s) are not on a whitelist (for example, we're not interested in links to spotify.com, or back to twitter.com)
Not a Retweet
In the old days retweets were simply reposting the same tweet with a RT prefix; now it's done as part of the Twitter model and Twitter clients display the original tweet with the retweeter shown. In the background though, the JSON is different from an original tweet (i.e. not a retweet).
Original tweet:
Because we all know how "careful" Trump is about not being recorded when he's not aware of it. #BillyBush #GoldenGate
— George Takei (@GeorgeTakei) January 12, 2017
{
"created_at": "Thu Jan 12 00:36:22 +0000 2017",
"id": 819342218611728384,
"id_str": "819342218611728384",
"text": "Because we all know how \"careful\" Trump is about not being recorded when he's not aware of it. #BillyBush #GoldenGate",
[...]
Retweet:
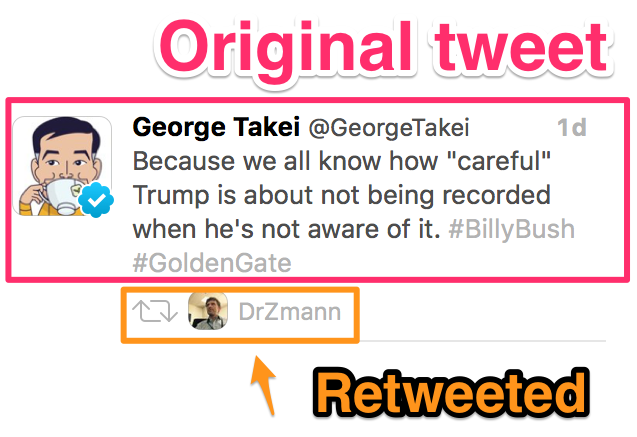
{
"created_at": "Thu Jan 12 14:40:44 +0000 2017",
"id": 819554713083461632,
"id_str": "819554713083461632",
"text": "RT @GeorgeTakei: Because we all know how \"careful\" Trump is about not being recorded when he's not aware of it. #BillyBush #GoldenGate",
[...]
"retweeted_status": {
"created_at": "Thu Jan 12 00:36:22 +0000 2017",
"id": 819342218611728384,
"id_str": "819342218611728384",
"text": "Because we all know how \"careful\" Trump is about not being recorded when he's not aware of it. #BillyBush #GoldenGate",
[...]
So retweets have an additional set of elements in the JSON body, under the retweeted_status element. We can pick this out using the get method as seen in this code snippet, where tweet is a Python object created from a json.loads from the JSON of the tweet:
if tweet.get('retweeted_status'):
print 'Tweet is a retweet'
else:
print 'Tweet is original'
Contains a URL, and URL is not on Whitelist
Twitter are very good to us in the JSON they supply for each tweet. Every possible attribute of the tweet is encoded as elements in the JSON, meaning that we don't have to do any nasty parsing of the tweet text itself. To find out if there are URLs in the tweet, we just check the entities.urls element, and iterate through the array if present.
if not tweet.get('entities'):
print 'no entities element'
else:
if not tweet.get('entities').get('urls'):
print 'no entities.urls element'
The URL itself is again provided to us by Twitter as the expanded_url within the urls array, and using the urlsplit library as I did previously we can extract the domain:
for url in tweet['entities']['urls']:
expanded_url = url['expanded_url']
domain = urlsplit(expanded_url).netloc
With the domain extracted, we can then compare it to a predefined whitelist so that we don't pick up tweets that are just linking back to sites such as Spotify, iTunes, etc. Here I'm using the Python set type and issubset method to compare the list of domain(s) that I've extracted from the tweet into the url_info list, against the whitelist:
if set(url_info['domain']).issubset(domain_whitelist):
print 'All domains whitelisted'
The Stream Processing Bit
With me so far? We've looked at the requirements for what our stream processing needs to do, and worked out the prototype code that will do this. Now we can jump into the actual streaming code. You can see the actual notebook here if you want to try this yourself.
Job control variables
batchIntervalSec=30
windowIntervalSec=21600 # Six hours
app_name = 'spark_twitter_enrich_and_count_rm_01e'
Make Kafka available to Jupyter
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.2 pyspark-shell'
os.environ['PYSPARK_PYTHON'] = '/opt/conda/envs/python2/bin/python'
Import dependencies
As well as Spark libraries, we're also bringing in the KafkaProducer library which will enable us to send messages to Kafka. This is in the kafka-python package. You can install this standalone on your system, or inline as done below.
# Necessary to make Kafka library available to pyspark
os.system("pip install kafka-python")
# Spark
from pyspark import SparkContext
# Spark Streaming
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
# Kafka
from kafka import SimpleProducer, KafkaClient
from kafka import KafkaProducer
# json parsing
import json
# url deconstruction
from urlparse import urlsplit
# regex domain handling
import re
Define values to match
filters=[]
filters.append({"tag":"album","value": "Glory Days","match":["Glory Days","GloryDays"]})
filters.append({"tag":"artist","value": "Little Mix","match":["Little Mix","LittleMix","Litel Mixx"]})
filters.append({"tag":"track","value": "Shout Out To My Ex","match":["Shout Out To My Ex","Shout Out To My X","ShoutOutToMyEx","ShoutOutToMyX"]})
filters.append({"tag":"track","value": "F.U.","match":["F.U","F.U.","FU","F U"]})
filters.append({"tag":"track","value": "Touch","match":["Touch"]})
filters.append({"tag":"track","value": "Oops","match":["Oops"]})
Define whitelisted domains
domain_whitelist=[]
domain_whitelist.append("itun.es")
domain_whitelist.append("wikipedia.org")
domain_whitelist.append("twitter.com")
domain_whitelist.append("instagram.com")
domain_whitelist.append("medium.com")
domain_whitelist.append("spotify.com")
Function: Unshorten shortened URLs (bit.ly etc)
# Source: http://stackoverflow.com/a/4201180/350613
import httplib
import urlparse
def unshorten_url(url):
parsed = urlparse.urlparse(url)
h = httplib.HTTPConnection(parsed.netloc)
h.request('HEAD', parsed.path)
response = h.getresponse()
if response.status/100 == 3 and response.getheader('Location'):
return response.getheader('Location')
else:
return url
Function: Send messages to Kafka
To inspect the Kafka topics as messages are sent use:
kafka-console-consumer --zookeeper cdh57-01-node-01.moffatt.me:2181 --topic twitter_matched2
N.B. following the Design Patterns for using foreachRDD guide here.
# http://spark.apache.org/docs/latest/streaming-programming-guide.html#design-patterns-for-using-foreachrdd
def send_to_kafka_matched(partition):
from kafka import SimpleProducer, KafkaClient
from kafka import KafkaProducer
kafka_prod = KafkaProducer(bootstrap_servers='cdh57-01-node-01.moffatt.me:9092')
for record in partition:
kafka_prod.send('twitter_matched2', str(json.dumps(record)))
def send_to_kafka_notmatched(partition):
from kafka import SimpleProducer, KafkaClient
from kafka import KafkaProducer
kafka_prod = KafkaProducer(bootstrap_servers='cdh57-01-node-01.moffatt.me:9092')
for record in partition:
kafka_prod.send('twitter_notmatched2', str(record))
def send_to_kafka_err(partition):
from kafka import SimpleProducer, KafkaClient
from kafka import KafkaProducer
kafka_prod = KafkaProducer(bootstrap_servers='cdh57-01-node-01.moffatt.me:9092')
for record in partition:
kafka_prod.send('twitter_err2', str(record))
Function: Process each tweet
This is the main processing code. It implements all of the logic described in the requirements above. If a processing condition is not met, the function returns a negative code and description of the condition that was not met. Errors are also caught and returned.
You can see a syntax-highlighted version of the code in the notebook here.
def process_tweet(tweet):
# Check that there's a URLs in the tweet before going any further
if tweet.get('retweeted_status'):
return (-1,'retweet - ignored',tweet)
if not tweet.get('entities'):
return (-2,'no entities element',tweet)
if not tweet.get('entities').get('urls'):
return (-3,'no entities.urls element',tweet)
# Collect all the domains linked to in the tweet
url_info={}
url_info['domain']=[]
url_info['primary_domain']=[]
url_info['full_url']=[]
try:
for url in tweet['entities']['urls']:
try:
expanded_url = url['expanded_url']
except Exception, err:
return (-104,err,tweet)
# Try to resolve the URL (assumes it's shortened - bit.ly etc)
try:
expanded_url = unshorten_url(expanded_url)
except Exception, err:
return (-108,err,tweet)
# Determine the domain
try:
domain = urlsplit(expanded_url).netloc
except Exception, err:
return (-107,err,tweet)
try:
# Extract the 'primary' domain, e.g. www36.foobar.com -> foobar.com
#
# This logic is dodgy for UK domains (foo.co.uk, foo.org.uk, etc)
# since it truncates to the last two parts of the domain only (co.uk)
#
re_result = re.search('(\w+\.\w+)$',domain)
if re_result:
primary_domain = re_result.group(0)
else:
primary_domain = domain
except Exception, err:
return (-105,err,tweet)
try:
url_info['domain'].append(domain)
url_info['primary_domain'].append(primary_domain)
url_info['full_url'].append(expanded_url)
except Exception, err:
return (-106,err,tweet)
# Check domains against the whitelist
# If every domain found is in the whitelist, we can ignore them
try:
if set(url_info['primary_domain']).issubset(domain_whitelist):
return (-8,'All domains whitelisted',tweet)
except Exception, err:
return (-103,err,tweet)
# Check domains against the blacklist
# Unless a domain is found, we ignore it
#Only use this if you have first defined the blacklist!
#if not set(domain_blacklist).intersection(url_info['primary_domain']):
# return (-9,'No blacklisted domains found',tweet)
except Exception, err:
return (-102,err,tweet)
# Parse the tweet text against list of trigger terms
# --------------------
# This is rather messy iterative code that maybe can be optimised
#
# Because match terms are not just words, it's not enough to break
# up the tweet text into words and match against the filter list.
# Instead we have to take each filter term and see if it exists
# within the tweet text as a whole
#
# Using a set instead of list so that duplicates aren't added
#
matched=set()
try:
for f in filters:
for a in f['match']:
tweet_text = tweet['text']
match_text = a.decode('utf-8')
if match_text in tweet_text:
matched.add((f['tag'],f['value']))
except Exception, err:
return (-101,err,tweet)
#-----
# Add the discovered metadata into the tweet object that this function will return
try:
tweet['enriched']={}
tweet['enriched']['media_details']={}
tweet['enriched']['url_details']=url_info
tweet['enriched']['match_count']=len(matched)
for match in matched:
tweet['enriched']['media_details'][match[0]]=match[1]
except Exception, err:
return (-100,err,tweet)
return (len(matched),tweet)
Function: Streaming context definition
This is the function that defines the streaming context. It needs to be a function because we're using windowing and so the streaming context needs to be configured to checkpoint.
As well as processing inbound tweets, it performs counts of:
- Inbound
- Outbound, by type (match/no match/error)
- For matched tweets, top domains and artists
The code is commented inline to explain how it works. You can see a syntax-highlighted version of the code in the notebook here.
def createContext():
sc = SparkContext(appName="spark_twitter_enrich_and_count_01")
sc.setLogLevel("WARN")
ssc = StreamingContext(sc, batchIntervalSec)
# Define Kafka Consumer and Producer
kafkaStream = KafkaUtils.createStream(ssc, 'cdh57-01-node-01.moffatt.me:2181', app_name, {'twitter':1})
## Get the JSON tweets payload
## >>TODO<< This is very brittle - if the Kafka message retrieved is not valid JSON the whole thing falls over
tweets_dstream = kafkaStream.map(lambda v: json.loads(v[1]))
## -- Inbound Tweet counts
inbound_batch_cnt = tweets_dstream.count()
inbound_window_cnt = tweets_dstream.countByWindow(windowIntervalSec,batchIntervalSec)
## -- Process
## Match tweet to trigger criteria
processed_tweets = tweets_dstream.\
map(lambda tweet:process_tweet(tweet))
## Send the matched data to Kafka topic
## Only treat it as a match if we hit at least two of the three possible matches (artist/track/album)
##
## _The first element of the returned object is a count of the number of matches, or a negative
## to indicate an error or no URL content in the tweet._
##
## _We only want to send the actual JSON as the output, so use a `map` to get just this element_
matched_tweets = processed_tweets.\
filter(lambda processed_tweet:processed_tweet[0]>1).\
map(lambda processed_tweet:processed_tweet[1])
matched_tweets.foreachRDD(lambda rdd: rdd.foreachPartition(send_to_kafka_matched))
matched_batch_cnt = matched_tweets.count()
matched_window_cnt = matched_tweets.countByWindow(windowIntervalSec,batchIntervalSec)
## Set up counts for matched metadata
##-- Artists
matched_artists = matched_tweets.map(lambda tweet:(tweet['enriched']['media_details']['artist']))
matched_artists_batch_cnt = matched_artists.countByValue()\
.transform((lambda foo:foo.sortBy(lambda x:-x[1])))\
.map(lambda x:"Batch/Artist: %s\tCount: %s" % (x[0],x[1]))
matched_artists_window_cnt = matched_artists.countByValueAndWindow(windowIntervalSec,batchIntervalSec)\
.transform((lambda foo:foo.sortBy(lambda x:-x[1])))\
.map(lambda x:"Window/Artist: %s\tCount: %s" % (x[0],x[1]))
##-- Domains
## Since url_details.primary_domain is an array, need to flatMap here
matched_domains = matched_tweets.flatMap(lambda tweet:(tweet['enriched']['url_details']['primary_domain']))
matched_domains_batch_cnt = matched_domains.countByValue()\
.transform((lambda foo:foo.sortBy(lambda x:-x[1])))\
.map(lambda x:"Batch/Domain: %s\tCount: %s" % (x[0],x[1]))
matched_domains_window_cnt = matched_domains.countByValueAndWindow(windowIntervalSec,batchIntervalSec)\
.transform((lambda foo:foo.sortBy(lambda x:-x[1])))\
.map(lambda x:"Window/Domain: %s\tCount: %s" % (x[0],x[1]))
## Display non-matches for inspection
##
## Codes less than zero but greater than -100 indicate a non-match (e.g. whitelist hit), but not an error
nonmatched_tweets = processed_tweets.\
filter(lambda processed_tweet:(-99<=processed_tweet[0]<=1))
nonmatched_tweets.foreachRDD(lambda rdd: rdd.foreachPartition(send_to_kafka_notmatched))
nonmatched_batch_cnt = nonmatched_tweets.count()
nonmatched_window_cnt = nonmatched_tweets.countByWindow(windowIntervalSec,batchIntervalSec)
## Print any erroring tweets
##
## Codes less than -100 indicate an error (try...except caught)
errored_tweets = processed_tweets.\
filter(lambda processed_tweet:(processed_tweet[0]<=-100))
errored_tweets.foreachRDD(lambda rdd: rdd.foreachPartition(send_to_kafka_err))
errored_batch_cnt = errored_tweets.count()
errored_window_cnt = errored_tweets.countByWindow(windowIntervalSec,batchIntervalSec)
## Print counts
inbound_batch_cnt.map(lambda x:('Batch/Inbound: %s' % x))\
.union(matched_batch_cnt.map(lambda x:('Batch/Matched: %s' % x))\
.union(nonmatched_batch_cnt.map(lambda x:('Batch/Non-Matched: %s' % x))\
.union(errored_batch_cnt.map(lambda x:('Batch/Errored: %s' % x)))))\
.pprint()
inbound_window_cnt.map(lambda x:('Window/Inbound: %s' % x))\
.union(matched_window_cnt.map(lambda x:('Window/Matched: %s' % x))\
.union(nonmatched_window_cnt.map(lambda x:('Window/Non-Matched: %s' % x))\
.union(errored_window_cnt.map(lambda x:('Window/Errored: %s' % x)))))\
.pprint()
matched_artists_batch_cnt.pprint()
matched_artists_window_cnt.pprint()
matched_domains_batch_cnt.pprint()
matched_domains_window_cnt.pprint()
return ssc
Start the streaming context
ssc = StreamingContext.getOrCreate('/tmp/%s' % app_name,lambda: createContext())
ssc.start()
ssc.awaitTermination()
Stream Output
Counters
From the stdout of the job we can see the simple counts of inbound and output splits, both per batch and accumulating window:
-------------------------------------------
Time: 2017-01-13 11:50:30
-------------------------------------------
Batch/Inbound: 9
Batch/Matched: 0
Batch/Non-Matched: 9
Batch/Errored: 0
-------------------------------------------
Time: 2017-01-13 11:50:30
-------------------------------------------
Window/Inbound: 9
Window/Non-Matched: 9
-------------------------------------------
Time: 2017-01-13 11:51:00
-------------------------------------------
Batch/Inbound: 21
Batch/Matched: 0
Batch/Non-Matched: 21
Batch/Errored: 0
-------------------------------------------
Time: 2017-01-13 11:51:00
-------------------------------------------
Window/Inbound: 30
Window/Non-Matched: 30
The details of identified artists within tweets is also tracked, per batch and accumulated over the window period (6 hours, in this example)
-------------------------------------------
Time: 2017-01-12 12:45:30
-------------------------------------------
Batch/Artist: Major Lazer Count: 4
Batch/Artist: David Bowie Count: 1
-------------------------------------------
Time: 2017-01-12 12:45:30
-------------------------------------------
Window/Artist: Major Lazer Count: 1320
Window/Artist: Drake Count: 379
Window/Artist: Taylor Swift Count: 160
Window/Artist: Metallica Count: 94
Window/Artist: David Bowie Count: 84
Window/Artist: Lady Gaga Count: 37
Window/Artist: Pink Floyd Count: 11
Window/Artist: Kate Bush Count: 10
Window/Artist: Justice Count: 9
Window/Artist: The Weeknd Count: 8
Kafka Output
Matched
The matched Kafka topic holds a stream of tweets in JSON format, with the discovered metadata (artist/album/track) added. I'm using the Kafka console consumer to view the contents, parsed through jq to show just the tweet text and metadata that has been added.
kafka-console-consumer --zookeeper cdh57-01-node-01.moffatt.me:2181 \
--topic twitter_matched1 \
--from-beginning|jq -r "[.text,.enriched.url_details.primary_domain[0],.enriched.media_details.artist,.enriched.media_details.album,.enriched.media_details.track,.enriched.match_count] "
[
"Million Reasons by Lady Gaga - this is horrendous sorry @ladygaga https://t.co/rEtePIy3OT",
"youtube.com",
"https://www.youtube.com/watch?v=NvMoctjjdhA&feature=youtu.be",
"Lady Gaga",
null,
"Million Reasons",
2
]
Non-Matched
On our Kafka topics outbound we can see the non-matched messages. Probably you'd disable this stream once the processing logic was finalised, but it's useful to be able to audit and validate the reasons for non-matches. Here a retweet is ignored, and we can see it's a retweet from the RT prefix of the text field. The -1 is the return code from the process_tweets function denoting a non-match:
(-1, 'retweet - ignored', {u'contributors': None, u'truncated': False, u'text': u'RT @ChartLittleMix: Little Mix adicionou datas para a Summer Shout Out 2017 no Reino Unido https://t.co/G4H6hPwkFm', u'@timestamp': u'2017-01-13T11:45:41.000Z', u'is_quote_status': False, u'in_reply_to_status_id': None, u'id': 819873048132288513, u'favorite_count': 0, u'source':
Summary
In this article we've built on the foundations of the initial exploration of Spark Streaming on Python, expanding it out to address a real-world processing requirement. Processing unbounded streams of data this way is not as complex as you may think, particularly for the benefits that it can yield in reducing the latencies between an event occuring and taking action from it.
We've not touched on some of the more complex areas, such as scaling this up to multiple Spark nodes, partitioned Kafka topics, and so on - that's another [kafka] topic (sorry...) for another day. The code itself is also rudimentary - before moving it into Production there'd be some serious refactoring and optimisation review to be performed on it.
You can find the notebook for this article here, and the previous article's here.
If you'd like more information on how Rittman Mead can help your business get the most of out its data, please do get in touch!