Democratize Data Science with Oracle Analytics Cloud - Predictions and Final Considerations


Oracle Analytics Cloud as an enabler for Data Science: this is the third post of a series which started with Episode I where we discussed the path from a Data Analyst to a Data Scientist and how to start a Data Science journey with OAC. Episode II was focused on Feature Engineering, Data Analytics and Machine Learning, showing how those steps can be performed in OAC using a visual and easily understandable interface.
This last post will focus on how to perform Predictions in OAC and lastly, it will analyze how the Data Science option provided by OAC can fit in a corporate Data Science Strategy.
Step #6: Predict
In the second part of the blog series, we understood how to train a model and evaluate the scoring predictions via OAC. It's important to note that the various models we created are stored as independent objects in OAC: they will not be changed by modification or deletion of the DataFlow that originated them. We can set the sharing permissions directly in the Model Inspect window.
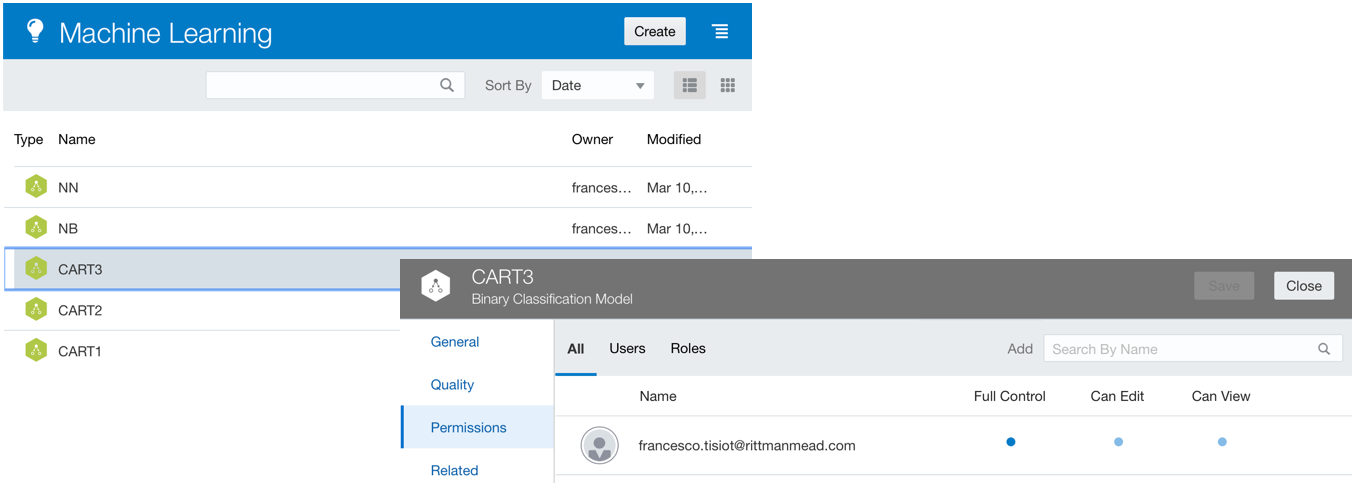
Note: It's worth mentioning that models are only identified by Model Name so multiple DataFlows generating models with the same name will be overwriting the same object.
As for model training, also for Prediction OAC provides two methods: On the Fly or via DataFlow. To create a project using On The Fly method, do the following:
- Select Create Scenario
- Select an ML Model from the list
- Associate the columns used for the Model training with columns coming from the dataset
- Start using the predicted fields in one (or more) visualization
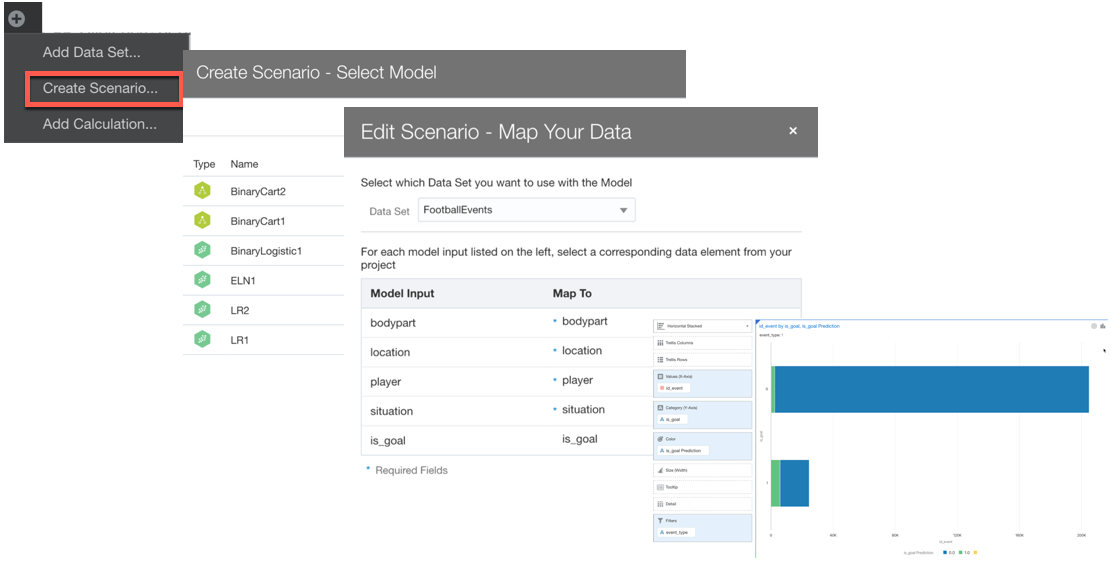
The On the Fly method works well and can add multiple scenarios at the same time, however, it has two disadvantages:
- The prediction is done at run time: the Python code behind the model is executed for every analysis and after every refresh, which could make the visualization time consuming and resource hungry to deliver.
- It's difficult to create new formulas using predictions and source dataset: providing a prediction is only part of the game, as Analysts, we may want to create complex calculations dependent on both columns coming from the predictions and the original dataset. This is possible (the prediction is done via an
EVALUATE_SCRIPTwhich can be found in the Developer view) but it's very hard and error prone since the columns coming from the evaluation are not provided in the Project's code editor for new columns.
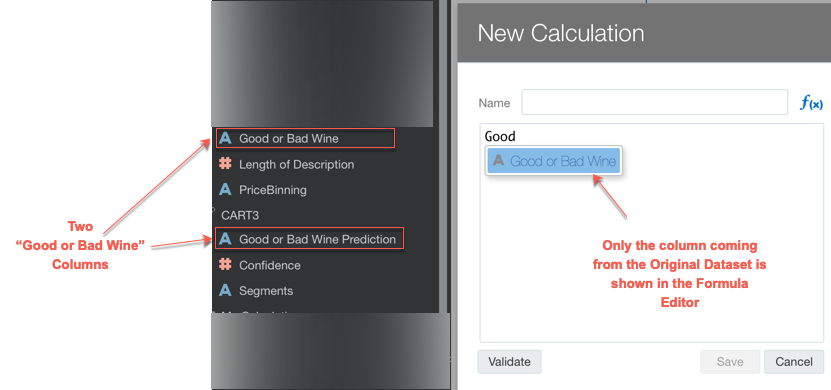
The second point mentioned is not an actual disadvantage of the method itself and mainly related to the editor implementation which I hope it will be fixed in a future release.
Both the above disadvantages are addressed by the "Batch" mode using DataFlow. In DataFlow there is the Apply Model step which follows the same logic as before:
- Select Apply Model
- Select an ML Model from the list
- Associate the columns used for the Model training with columns coming from the dataset
- Select which Columns from the prediction to include in the target dataset
- Store the resulting dataset
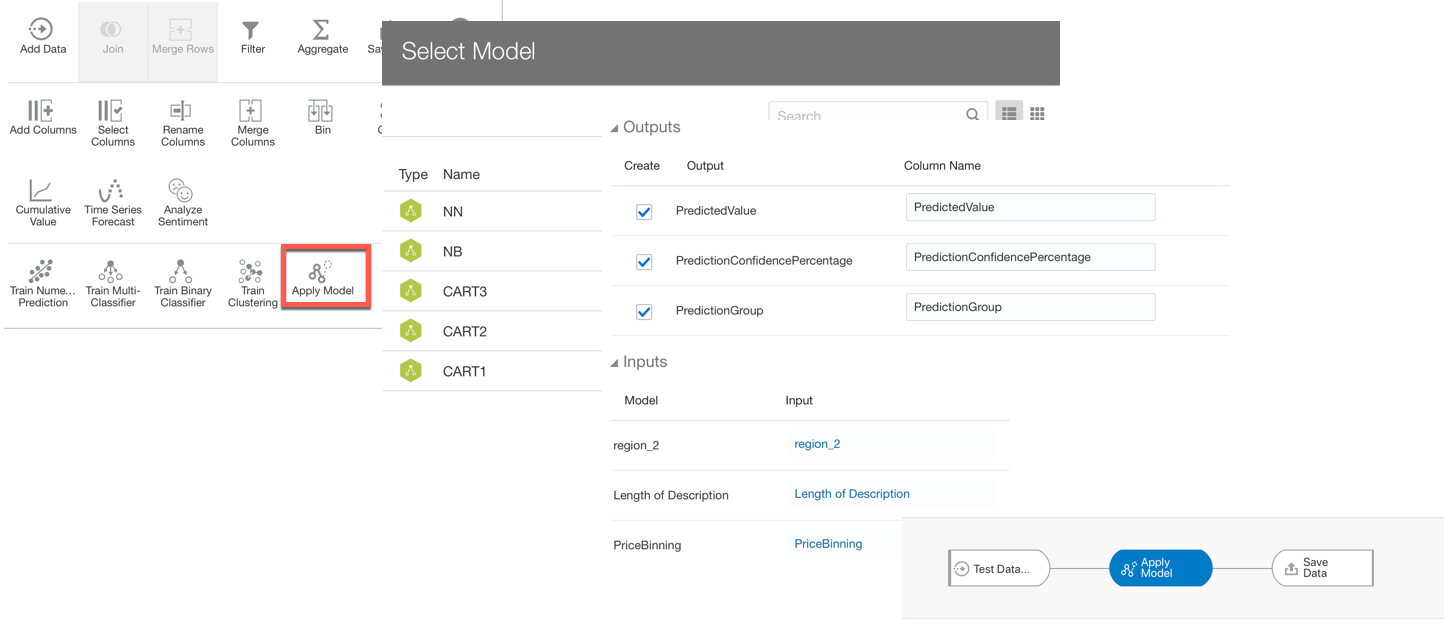
The DataFlow method will apply the predictions only once and store them in a new dataset. Since the resulting dataset will contain both columns from the original dataset as well as the ones from the prediction any combined metric can easily be created as part of the DataFlow or directly in the Project visualization mode. It's worth mentioning that the DataFlow method can't be executed in situations where real-time data is analyzed thus the predictions need to happen at query time. However Incremental DataFlows can be scheduled at every few min intervals, thus near-real-time analytics cases could be addressed.
Final Considerations
Bringing Data Science to people, this is one of Oracle Analytics Cloud's missions: providing automated insights about datasets, training and evaluating Machine Learning Models in an easy and low-code interface, all included within the same tool Business Analysts use in their day to day job. OAC does a great job by offering a rich and powerful set of options via the same GUI Business Users are already experiencing.
Other Data Science Use Cases and Alternatives
We can't, however, expect OAC to cover all the Data Science use cases. OAC is perfect for the initial Data Science enablement, providing tools to get deep insights on existing datasets and create fairly complex Machine Learning models. On the other hand when dealing with massive amounts of data, when complex data transformations need to happen or when parameter fine-tuning for perfect performances is needed, then OAC may not be the right tool.
When running any model training or prediction, OAC is extracting the data, executing the training/scoring python code on the OAC server, and then either displaying or storing the data. OAC is basically moving the data to ML which is inefficient for huge data volumes. In such cases, the approach of moving Machine Learning to Data, by using Oracle Advanced Analytics directly in the Database should be the selected one. Moreover, for more sophisticated use cases, usually in the hands of Data Scientist, Oracle provides Oracle Machine Learning, a Machine Learning SQL notebook based on Apache Zeppelin on top of Oracle Autonomous Data Warehouse.
Worth also mentioning that, for typical code-based Data Scientist type work, Oracle R Enterprise offers the powerful functions of R optimized for the usage in the Oracle database. If you're more a Python guy, Oracle Advanced Analytics contains Oracle Machine Learning for Python (OML4Py) enabling to run an optimized Python version directly in the Oracle Database.
The bonus point of doing Machine Learning in the database is that predictions are usually only a function-call away, thus can be packaged in a view and consumed as standard database objects by Oracle Analytics Cloud users. This allows us to mix and match various Machine Learning creation flows depending on the complexity, amount of data and skillset of the team involved. On a future outlook, Oracle Data Science Cloud is also coming soon, providing collaborative end-to-end ML environment in the cloud.
Conclusion
Oracle Analytics Cloud is the perfect tool to speed up a company's path to Data Science: not only it empowers Business Users with Augmented Analytics, Machine Learning training and prediction flows, it also provides an easy interface to learn tasks like Data Cleaning, Feature Engineering and Model Selection & Evaluation which are proper of Data Scientists. Furthermore, including OAC in an ecosystem with Oracle Advanced Analytics and Oracle Machine Learning, provides a unique, consistent and connected solution capable of handling all Data Science company needs.
In a future blog post series I'll be doing a technical deep dive on how ML works under the hood and how you can extend it with custom Models. Check this space for news!