
Sql2Odi, Part Two: Translate a complex SELECT statement into an ODI Mapping
What we call a complex SQL SELECT statement really depends on the context. When talking about translating SQL queries into ODI Mappings, pretty much anything that goes beyond a trivial SELECT * FROM <a_single_source_table> can be called complex.
SQL statements are meant for humans to be written and for RDBMS servers like Oracle Database to be understood and executed. RDBMS servers benefit from a wealth of knowledge about the database we are querying and are willing to give us a lot of leeway about how we write those queries, to make it as easy as possible for us. Let me show you what I mean:
SELECT
FIRST_NAME,
AGE - '5' LIE_ABOUT_YOUR_AGE,
REGION.*
FROM
CUSTOMER
INNER JOIN REGION ON "CUSTOMER_REGION_ID" = REGION.REGION_ID
We are selecting from two source tables, yet we have not bothered about specifying source tables for columns (apart from one instance in the filter). That is fine - the RDBMS server can fill that detail in for us by looking through all source tables, whilst also checking for column name duplicates. We can use numeric strings like '567' instead of proper numbers in our expressions, relying on the server to perform implicit conversion. And the * will always be substituted with a full list of columns from the source table(s).
All that makes it really convenient for us to write queries. But when it comes to parsing them, the convenience becomes a burden. However, despite lacking the knowledge the the RDBMS server possesses, we can still successfully parse and then generate an ODI Mapping for quite complex SELECT statements. Let us have a look at our Sql2Odi translator handling various challenges.
Rittman Mead's Sql2Odi Translator in Action
Let us start with the simplest of queries:
SELECT
ORDER_ID,
STATUS,
ORDER_DATE
FROM
ODI_DEMO.SRC_ORDERS
The result in ODI looks like this:
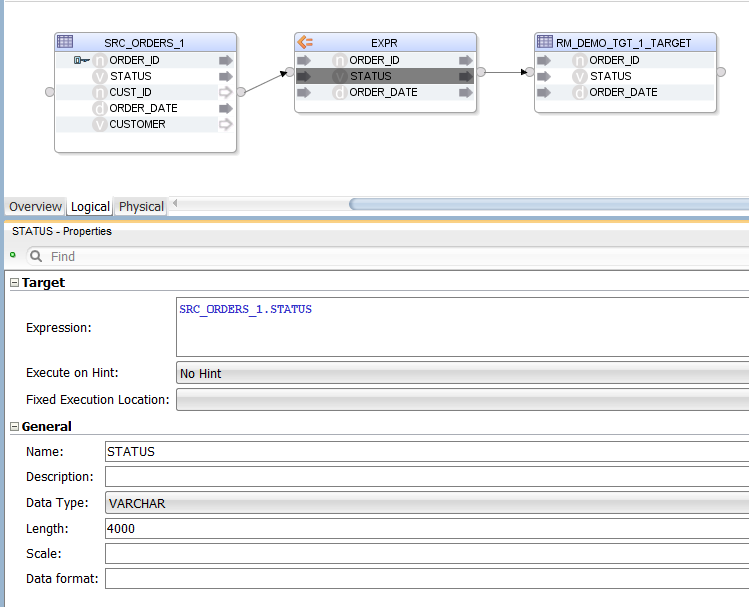
Sql2Odi has created an Expression, in which we have the list of selected columns. The columns are mapped to the target table by name (alternatively, they could be mapped by position). The target table is provided in the Sql2Odi metadata table along with the SELECT statement and other Mapping generation related configuration.
Can we replace the list of columns in the SELECT list with a *?
SELECT * FROM ODI_DEMO.SRC_ORDERS
The only difference from the previously generated Mapping is that the Expression now has a full list of source table columns. We could not get the list of those columns while parsing the statement but we can look them up from the source ODI Datastore when generating the mapping. Groovy!
Let us increase the complexity by adding a JOIN, a WHERE filter and an ORDER BY clause to the mix:
SELECT
SRC_ORDERS.*
FROM
ODI_DEMO.SRC_ORDERS
LEFT JOIN ODI_DEMO.SRC_CUSTOMER CUST ON
SRC_ORDERS.CUST_ID = CUST.CUSTID
WHERE
CUST.AGE BETWEEN 20 AND 50
ORDER BY CUST.AGE
The Mapping looks more crowded now. Notice that we are selecting * from one source table only - again, that is not something that the parser alone can handle.
We are not using ODI Mapping Datasets - a design decision was made not to use them because of the way Sql2Odi handles subqueries.
Speaking of subqueries, let us give them a try - in the FROM clause you can source your data not only from tables but also from sub-SELECT statements or subqueries.
SELECT
LAST_NAME,
FIRST_NAME,
LAST_NAME || ' ' || FIRST_NAME AS FULL_NAME,
AGE,
COALESCE(LARGE_CITY.CITY, ALL_CITY.CITY) CITY,
LARGE_CITY.POPULATION
FROM
ODI_DEMO.SRC_CUSTOMER CST
INNER JOIN ODI_DEMO.SRC_CITY ALL_CITY ON ALL_CITY.CITY_ID = CST.CITY_ID
LEFT JOIN (
SELECT
CITY_ID,
UPPER(CITY) CITY,
POPULATION
FROM ODI_DEMO.SRC_CITY
WHERE POPULATION > 750000
) LARGE_CITY ON LARGE_CITY.CITY_ID = CST.CITY_ID
WHERE AGE BETWEEN 25 AND 45
As we can see, a sub-SELECT statement is handled the same way as a source table, the only difference being that we also get a WHERE Filter and an Expression that together give us the data set of the subquery. All Components representing the subquery are suffixed with a 3 or _3_1 in the Mapping.
Now let us try Aggregates.
SELECT
REGION,
SUM(POPULATION) TOTAL_POPULATION,
ROUND(MAX(SRC_CITY.POPULATION) / 1000000) BIGGEST_CITY_POPULATION_K,
ROUND(MIN(SRC_CITY.POPULATION) / 1000000) SMALLEST_CITY_POPULATION_K
FROM
ODI_DEMO.SRC_CITY
INNER JOIN ODI_DEMO.SRC_REGION ON SRC_CITY.REGION_ID = SRC_REGION.REGION_ID
WHERE
CITY_ID > 20 AND
"SRC_CITY"."CITY_ID" < 1000 AND
ODI_DEMO.SRC_CITY.CITY_ID != 999 AND
COUNTRY IN ('USA', 'France', 'Germany', 'Great Britain', 'Japan')
GROUP BY
REGION
HAVING
SUM(POPULATION) > 10000 AND
MIN(SRC_CITY.POPULATION) > 100 AND
MAX("POPULATION") > 1000 AND
AVG(ODI_DEMO.SRC_CITY.POPULATION) >= 5
This time, instead of an Expression we have an Aggregate. The parser has no problem handling the many different "styles" of column references provided in the HAVING clause - all of them are rewritten to be understood by ODI.
Now let us throw different Expressions at it, to see how well they are handled.
SELECT
REG_COUNTRY.COUNTRY,
REG_COUNTRY.LOC,
REG_COUNTRY.NR_OF_EURO_REG,
LAST_NAME,
LAST_NAME AS SURNAME,
FIRST_NAME,
FIRST_NAME || ' ' || LAST_NAME FULL_NAME,
'String concatenation' || ' ' || FIRST_NAME || ' demo.' CONCAT_STRING,
UPPER(LAST_NAME) || ' in UpperCase' AS LAST_NAME_UPPER,
SUBSTR(TRIM(UPPER(' Name: ' || LAST_NAME || ' ' || FIRST_NAME || ' ')), 2, 10) TEXT_FUNC,
TRANSLATE(UPPER(LAST_NAME), 'AEIOU', 'XXXXX') X_LAST_NAME,
LENGTH(FIRST_NAME || ' ' || LAST_NAME) FULL_NAME_LEN,
10 + LENGTH(FIRST_NAME || ' ' || LAST_NAME) FULL_NAME_LEN_10P,
10 * LENGTH(FIRST_NAME || ' ' || LAST_NAME) FULL_NAME_LEN_10T,
INSTR(UPPER(LAST_NAME), 'MC') MC_IN_LAST,
1 + 2 + 3 + 4 +5+6+7 SIMP_SUM,
1+2-3*4/5+(6*7+8-9)/(1+2+3) SUM2,
ROUND(1+2-3*4/5+(6*7+8-9)/(1+2+3)) SUM2_ROUND1,
ROUND(1+2-3*4/5+(6*7+8-9)/(1+2+3), 2) SUM2_ROUND2,
FLOOR(ROUND(1+2-3*4/5+(6*7+8-9), 2) / ROUND((1+2+3), 2)) SUM2_ROUND3,
SYSDATE DATE_NOW,
SYSDATE AS CUR_DAT,
1 + SYSDATE AS CURD_1,
SYSDATE + 4 AS CURD_4,
CURRENT_DATE AS CUR_ALT,
ADD_MONTHS(SYSDATE, 1) CURD_1M,
CURRENT_TIMESTAMP STAMP_NOW,
LAST_DAY(SYSDATE) LAST_CURD,
NEXT_DAY(LAST_DAY(SYSDATE), 2) LAST_NEXT_CURD,
TO_CHAR(LAST_DAY(ADD_MONTHS(SYSDATE, 1)), 'DD/MM/YYYY') CHAR_CURT,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN ROUND(1+2-3*4/5+(6*7+8-9)/(1+2+3), 2)
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN FLOOR(345.56)
WHEN REG_COUNTRY.COUNTRY = 'Germany' THEN MONTHS_BETWEEN(SYSDATE, SYSDATE+1000)
ELSE NULL
END SIM_CASE_NUM,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN NEXT_DAY(LAST_DAY(SYSDATE+5), 2)
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN NEXT_DAY(LAST_DAY(SYSDATE+40), 2)
ELSE NULL
END SIM_CASE_DATE,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN UPPER(FIRST_NAME || ' ' || LAST_NAME)
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN AGE || ' years of pain'
ELSE NULL
END SIM_CASE_CHAR,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN FIRST_NAME
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN LAST_NAME
ELSE NULL
END SIM_CASE_CHARCOL,
CASE
WHEN REG_COUNTRY.COUNTRY = 'USA' THEN NULL
WHEN REG_COUNTRY.COUNTRY = 'France' THEN AGE
WHEN REG_COUNTRY.COUNTRY = 'Great Britain' THEN AGE
ELSE NULL
END SIM_CASE_NUMCOL,
'123' * 10 IMPI_NUM1,
123 * '10' IMPI_NUM2
FROM
ODI_DEMO.SRC_CUSTOMER
INNER JOIN ODI_DEMO.SRC_CITY ON SRC_CITY.CITY_ID = SRC_CUSTOMER.CITY_ID
INNER JOIN ODI_DEMO.SRC_REGION ON SRC_CITY.REGION_ID = SRC_REGION.REGION_ID
INNER JOIN (
SELECT COUNTRY_ID, COUNTRY, 'Europe' LOC, COUNT(DISTINCT REGION_ID) NR_OF_EURO_REG FROM ODI_DEMO.SRC_REGION WHERE COUNTRY IN ('France','Great Britain','Germany') GROUP BY COUNTRY_ID, COUNTRY
UNION
SELECT DISTINCT COUNTRY_ID, COUNTRY, 'Non-Europe' LOC, 0 NR_OF_EURO_REG FROM ODI_DEMO.SRC_REGION WHERE COUNTRY IN ('USA','Australia','Japan')
ORDER BY NR_OF_EURO_REG
) REG_COUNTRY ON SRC_REGION.COUNTRY_ID = REG_COUNTRY.COUNTRY_ID
WHERE
REG_COUNTRY.COUNTRY IN ('USA', 'France', 'Great Britain', 'Germany', 'Australia')
ORDER BY
LOC, COUNTRY
Notice that, apart from parsing the different Expressions, Sql2Odi also resolves data types:
1 + SYSDATEis correctly resolved as a DATE value whereasTO_CHAR(LAST_DAY(ADD_MONTHS(SYSDATE, 1)), 'DD/MM/YYYY') CHAR_CURTis recognised as aVARCHARvalue - because of theTO_CHARfunction;LAST_NAMEandFIRST_NAMEare resolved asVARCHARvalues because that is their type in the source table;AGE || ' years of pain'is resolved as aVARCHARdespiteAGEbeing a numeric value - because of the concatenation operator;- More challenging is data type resolution for
CASEstatements, but those are handled based on the datatypes we encounter in theTHENandELSEparts of the statement.
Also notice that we have a UNION joiner for the two subqueries - that is translated into an ODI Set Component.
As we can see, Sql2Odi is capable of handling quite complex SELECT statements. Alas, that does not mean it can handle 100% of them - Oracle hierarchical queries, anything involving PIVOTs, the old Oracle (+) notation, the WITH statement - those are a few examples of constructs Sql2Odi, as of this writing, cannot yet handle.
Sql2Odi - what is under the hood?
Scala's Combinator Parsing library was used for lexical and syntactic analysis. We went with a context-free grammar definition for the SELECT statement, because our goal was never to establish if a SELECT statement is 100% valid - only the RDBMS server can do that. Hence we start with the assumption that the SELECT statement is valid. An invalid SELECT statement, depending on the nature of the error, may or may not result in a parsing error.
For example, the Expression ADD_MONTHS(CUSTOMER.FIRST_NAME, 3) is obviously wrong but our parser assumes that the FIRST_NAME column is a DATE value.
Part of the parsing-translation process was also data type recognition. In the example above, the parser recognises that the function being used returns a datetime value. Therefore it concludes that the whole expression, regardless of what the input to that function is - a column, a constant or another complex Expression - will always be a DATE value.
The output of the Translator is a structured data value containing definitions for ODI Mapping Components and their joins. I chose JSON format but XML would have done the trick as well.
The ODI Mapping definitions are then read by a Groovy script from within ODI Studio and Mappings are generated one by one.
Mapping generation takes much longer than parsing. Parsing for a mapping is done in a split second whereas generating an ODI Mapping, depending on its size, can take a couple of seconds.
Conclusion
It is possible to convert SQL SELECT statements to ODI Mappings, even quite complex ones. This can make migrations from SQL-based legacy ETL tools to ODI much quicker, allows to refactor an SQL-based ETL prototype to ODI without having to implement the same data extraction and transformation logic twice.