A quick way of generating Informatica PowerCenter Mappings from a template

Generating Informatica PowerCenter Content - the Options
In our blogs we have discussed the options for Oracle Data Integrator (ODI) content generation here and here. Our go-to method is to use the ODI Java SDK, which allows querying, manipulating and generating new ODI content.
Can we do the same with Informatica PowerCenter? In the older PC versions there was the Design API that enabled browsing the repository and creating new content. However, I have never used it. My impression is that Oracle APIs are more accessible than Informatica APIs in terms of documentation, help available online and availability for download and tryout.
If we want to browse the PowerCenter repository content, there is an easy way - query the repository database. But what about content generation? Who will be brave or foolish enough to insert records directly into a repository database!? Fortunately, there is a way, and a fairly easy one, if you don't mind doing a bit of Python scripting.
Generate PowerCenter Mappings - an Overview
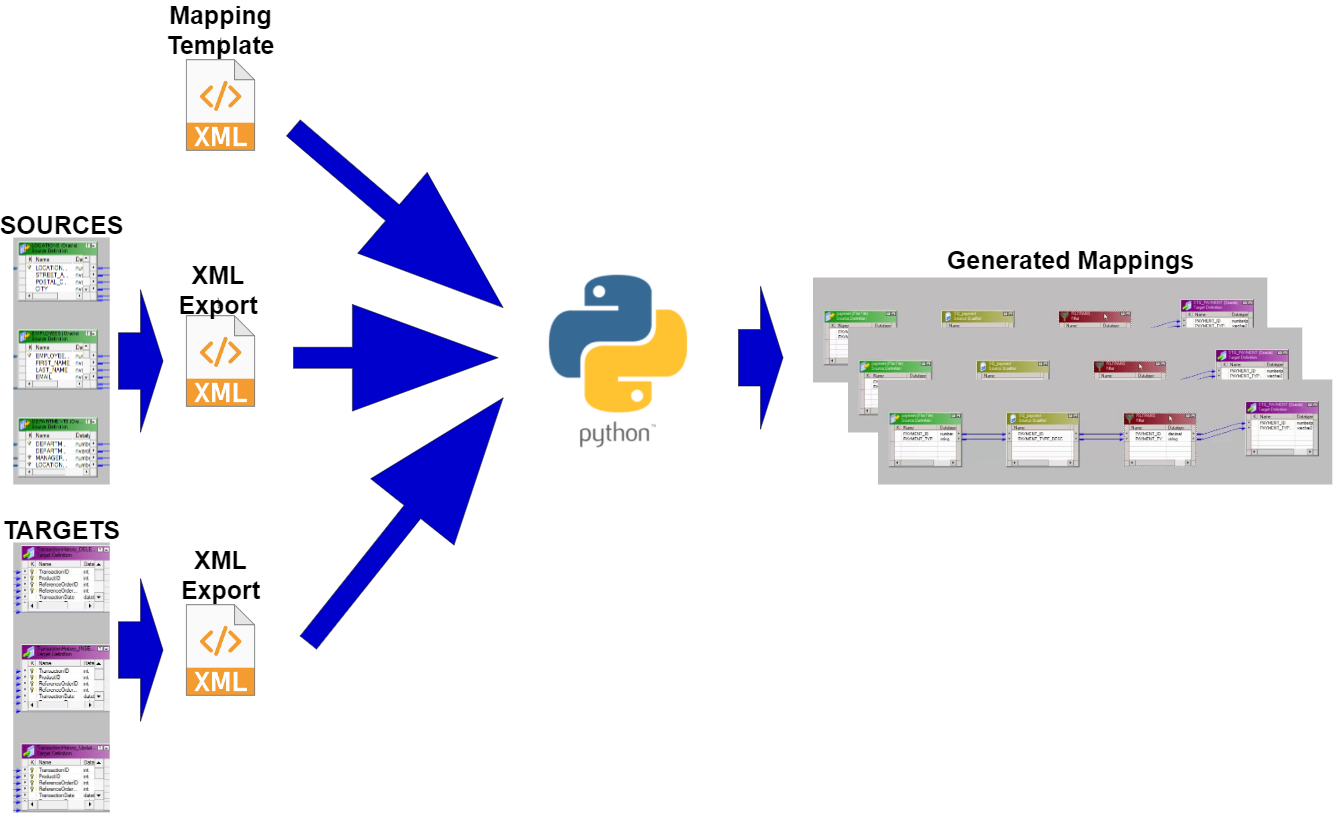
Selective Informatica PC repository migrations are done via XML export and import - it is easy and mostly fool-proof. If we can generate XMLs for import, then we have found a way of auto-generating PowerCenter content. Informatica seems to support this approach by giving us nice, descriptive error messages if something is wrong with import XMLs. Only completely valid XMLs will import successfully. I have never managed to corrupt my Informatica repository with a dodgy XML import.
Let us look at an example - we need to extract a large number of OLTP tables to a Staging schema. The source and staging tables have very similar structures, except the staging tables have MD5 codes based on all non-key source fields to simplify change data capture (CDC) and also have the extract datetime.
- We start by creating a single mapping in Designer, test it, make sure we are 100% happy with it before proceeding further;
- We export the mapping in XML format and in the XML file we replace anything unique to the source and target table and their fields with placeholder tags:
[[EXAMPLE_TAG]]. (See the XML template example further down.) - Before we generate XMLs for all needed mappings, we need to import Source and Target table definitions from the databases. (We could, if we wanted, generate Source and Target XMLs ourselves but PC Designer allows us to import tables in bulk, which is quicker and easer than generating the XMLs.)
- We export all Sources into a single XML file, e.g.
sources.xml. Same with all the Targets - they go intotargets.xml. (You can select multiple objects and export in a single XML in Repository Manager.) The Source XML file will serve as a driver for our Mapping generation - all Source tables in thesources.xmlfile will have a Mapping generated for them. - We run a script that iterates through all source tables in the source XML, looks up its target in the targets XML and generates a mapping XML. (See the Python script example further down.) Note that both the Source and Target XML become part of the Mapping XML.
- We import the mapping XMLs. If we import manually via the Designer, we still save time in comparison to implementing the mappings in Designer one by one. But we can script the imports, thus getting both the generation and import done in minutes, by creating an XML Control File as described here.
A further improvement to the above would be reusable Session generation. We can generate Sessions in the very same manner as we generate Mappings.
The Implementation
An example XML template for a simple Source-to-Staging mapping that includes Source, Source Qualifier, Expression and Target:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE POWERMART SYSTEM "powrmart.dtd">
<POWERMART CREATION_DATE="05/26/2021 11:55:12" REPOSITORY_VERSION="188.97">
<REPOSITORY NAME="DemoETL" VERSION="188" CODEPAGE="UTF-8" DATABASETYPE="Oracle">
<FOLDER NAME="Extract" GROUP="" OWNER="Developer" SHARED="NOTSHARED" DESCRIPTION="" PERMISSIONS="rwx---r--" UUID="55321111-2222-4929-9fdc-bd0dfw245cd3">
[[SOURCE]]
[[TARGET]]
<MAPPING DESCRIPTION ="[[MAPPING_DESCRIPTION]]" ISVALID ="YES" NAME ="[[MAPPING_NAME]]" OBJECTVERSION ="1" VERSIONNUMBER ="2">
<TRANSFORMATION DESCRIPTION ="" NAME ="SQ_EXTRACT" OBJECTVERSION ="1" REUSABLE ="NO" TYPE ="Source Qualifier" VERSIONNUMBER ="1">
[[SQ_TRANSFORMFIELDS]]
<TABLEATTRIBUTE NAME ="Sql Query" VALUE =""/>
<TABLEATTRIBUTE NAME ="User Defined Join" VALUE =""/>
<TABLEATTRIBUTE NAME ="Source Filter" VALUE =""/>
<TABLEATTRIBUTE NAME ="Number Of Sorted Ports" VALUE ="0"/>
<TABLEATTRIBUTE NAME ="Tracing Level" VALUE ="Normal"/>
<TABLEATTRIBUTE NAME ="Select Distinct" VALUE ="NO"/>
<TABLEATTRIBUTE NAME ="Is Partitionable" VALUE ="NO"/>
<TABLEATTRIBUTE NAME ="Pre SQL" VALUE =""/>
<TABLEATTRIBUTE NAME ="Post SQL" VALUE =""/>
<TABLEATTRIBUTE NAME ="Output is deterministic" VALUE ="NO"/>
<TABLEATTRIBUTE NAME ="Output is repeatable" VALUE ="Never"/>
</TRANSFORMATION>
<TRANSFORMATION DESCRIPTION ="" NAME ="EXPTRANS" OBJECTVERSION ="1" REUSABLE ="NO" TYPE ="Expression" VERSIONNUMBER ="2">
[[EXP_TRANSFORMFIELDS]]
<TRANSFORMFIELD DATATYPE ="nstring" DEFAULTVALUE ="ERROR('transformation error')" DESCRIPTION ="" EXPRESSION ="[[MD5_EXPRESSION]]" EXPRESSIONTYPE ="GENERAL" NAME ="CDC_MD5" PICTURETEXT ="" PORTTYPE ="OUTPUT" PRECISION ="32" SCALE ="0"/>
<TRANSFORMFIELD DATATYPE ="date/time" DEFAULTVALUE ="ERROR('transformation error')" DESCRIPTION ="" EXPRESSION ="SYSTIMESTAMP()" EXPRESSIONTYPE ="GENERAL" NAME ="EXTRACT_DATE" PICTURETEXT ="" PORTTYPE ="OUTPUT" PRECISION ="29" SCALE ="9"/>
<TABLEATTRIBUTE NAME ="Tracing Level" VALUE ="Normal"/>
</TRANSFORMATION>
[[SOURCE_INSTANCE]]
<INSTANCE DESCRIPTION ="" NAME ="SQ_EXTRACT" REUSABLE ="NO" TRANSFORMATION_NAME ="SQ_EXTRACT" TRANSFORMATION_TYPE ="Source Qualifier" TYPE ="TRANSFORMATION">
<ASSOCIATED_SOURCE_INSTANCE NAME ="[[SOURCE_INSTANCE_NAME]]"/>
</INSTANCE>
<INSTANCE DESCRIPTION ="" NAME ="EXPTRANS" REUSABLE ="NO" TRANSFORMATION_NAME ="EXPTRANS" TRANSFORMATION_TYPE ="Expression" TYPE ="TRANSFORMATION"/>
[[TARGET_INSTANCE]]
[[SRC_2_SQ_CONNECTORS]]
[[SQ_2_EXP_CONNECTORS]]
[[EXP_2_TGT_CONNECTORS]]
<CONNECTOR FROMFIELD ="CDC_MD5" FROMINSTANCE ="EXPTRANS" FROMINSTANCETYPE ="Expression" TOFIELD ="CDC_MD5" TOINSTANCE ="[[TARGET_INSTANCE_NAME]]" TOINSTANCETYPE ="Target Definition"/>
<CONNECTOR FROMFIELD ="EXTRACT_DATE" FROMINSTANCE ="EXPTRANS" FROMINSTANCETYPE ="Expression" TOFIELD ="EXTRACT_DATE" TOINSTANCE ="[[TARGET_INSTANCE_NAME]]" TOINSTANCETYPE ="Target Definition"/>
<TARGETLOADORDER ORDER ="1" TARGETINSTANCE ="[[TARGET_INSTANCE_NAME]]"/>
<ERPINFO/>
<METADATAEXTENSION COMPONENTVERSION ="1000000" DATATYPE ="STRING" DESCRIPTION ="" DOMAINNAME ="User Defined Metadata Domain" ISCLIENTEDITABLE ="YES" ISCLIENTVISIBLE ="YES" ISREUSABLE ="YES" ISSHAREREAD ="NO" ISSHAREWRITE ="NO" MAXLENGTH ="256" NAME ="Extension" VALUE ="" VENDORNAME ="INFORMATICA"/>
</MAPPING>
</FOLDER>
</REPOSITORY>
</POWERMART>Python script snippets for generating Mapping XMLs based on the above template:
- To translate database types to Informatica data types:
mapDataTypeDict = {
"nvarchar": "nstring",
"date": "date/time",
"timestamp": "date/time",
"number": "decimal",
"bit": "nstring"
}2. Set up a dictionary of tags:
xmlReplacer = {
"[[SOURCE]]": "",
"[[TARGET]]": "",
"[[MAPPING_DESCRIPTION]]": "",
"[[MAPPING_NAME]]": "",
"[[SQ_TRANSFORMFIELDS]]": "",
"[[EXP_TRANSFORMFIELDS]]": "",
"[[MD5_EXPRESSION]]": "",
"[[SOURCE_INSTANCE]]": "",
"[[SOURCE_INSTANCE_NAME]]": "",
"[[TARGET_INSTANCE]]": "",
"[[TARGET_INSTANCE_NAME]]": "",
"[[SRC_2_SQ_CONNECTORS]]": "",
"[[SQ_2_EXP_CONNECTORS]]": "",
"[[EXP_2_TGT_CONNECTORS]]": ""
}3. We use the Source tables we extracted in a single XML file as our driver for Mapping creation:
sourceXmlFilePath = '.\\sources.xml'
# go down the XML tree to individual Sources
sourceTree = ET.parse(sourceXmlFilePath)
sourcePowerMart = sourceTree.getroot()
sourceRepository = list(sourcePowerMart)[0]
sourceFolder = list(sourceRepository)[0]
for xmlSource in sourceFolder:
# generate a Mapping for each Source
# We also need to go down the Field level:
for sourceField in xmlSource:
# field level operations4. Generate tag values. This particular example is of a Column-level tag, a column connector between Source Qualifier and Expression:
sqToExpConnectorTag = f'<CONNECTOR FROMFIELD ="{columnName}" FROMINSTANCE ="SQ_EXTRACT" FROMINSTANCETYPE ="Source Qualifier" TOFIELD ="{columnName}" TOINSTANCE ="EXPTRANS" TOINSTANCETYPE ="Expression"/>'5. We assign our tag values to the tag dictionary entries:
xmlReplacer["[[SQ_2_EXP_CONNECTORS]]"] = '\n'.join(sqToExpConnectors)6. We replace the tags in the XML Template with the values from the dictionary:
for replaceTag in xmlReplacer.keys():
mappingXml = mappingXml.replace(replaceTag, xmlReplacer[replaceTag])Interested in finding out more about our approach to generating Informatica content, contact us.