OpenAI Gives Vision to Oracle DB, Part 2: Analysing Image Data with GPT-4o


The Context
In my last blog post, we successfully loaded image data into an Oracle database table. Now, we will focus on building an Oracle function to connect this data with the OpenAI GPT-4o model for analysis. We will adapt the framework from a previous blog post where we used textual inputs, reusing and enhancing the same Java class for this task. The process for passing image data to OpenAI will mirror our previous work with text data.
Building the Java Method
This blog post requires that you already have built the Java class described in a previous blog post and are also familiar with compiling that class, packaging it into a jar file and uploading that jar to Oracle database - those same steps will be required for our work here. We will add a new method to that existing Java class, which is similar but perhaps a bit more polished than the previous method we had built.
Our work starts by defining a few private helper methods, to keep our main method lean and easy to read:
convertClobToString method - to convert Oracle CLOB value to Java String
private static String convertClobToString(Clob clob) throws SQLException, IOException {
try (Reader reader = clob.getCharacterStream()) {
StringBuilder sb = new StringBuilder();
char[] buffer = new char[1024];
int charsRead;
while ((charsRead = reader.read(buffer)) != -1) {
sb.append(buffer, 0, charsRead);
}
return sb.toString();
}
}- This method converts a java.sql.Clob object to a Java String.
- A lot of boilerplate code here, which is a shame. The now deprecated
oracle.sql.CLOBhad a single method for converting it to a String.
createOpenAIRequestPayload method - to build Payload for OpenAI Web API Request
private static JsonObject createOpenAIRequestPayload(String prompt, String base64Data) {
JsonObjectBuilder payload = Json.createObjectBuilder();
payload.add("model", "gpt-4o"); // gpt-4-turbo - more expensive and older, gpt-3.5-turbo-0125 - no vision
JsonArrayBuilder messages = Json.createArrayBuilder();
JsonObjectBuilder message = Json.createObjectBuilder();
message.add("role", "user");
JsonArrayBuilder content = Json.createArrayBuilder();
content.add(Json.createObjectBuilder().add("type", "text").add("text", prompt));
content.add(Json.createObjectBuilder()
.add("type", "image_url")
.add("image_url", Json.createObjectBuilder().add("url", "data:image/jpeg;base64," + base64Data)) // upload a binary JPEG image in base64 (text) encoding
);
message.add("content", content);
messages.add(message);
payload.add("messages", messages);
payload.add("max_tokens", 300);
return payload.build();
}- This method receives two input parameters - the textual prompt for the AI to know what to do with the image and the image in base64 format for secure web API transmission.
- It uses
JsonObjectBuilderfor efficient payload creation and attaches the image with the format specifier"data:image/jpeg;base64," + base64Data. - We are using the
gpt-4omodel. Alternatively, we could use thegpt-4-turbomodel, but it is twice as expensive and less capable. The powerful yet cheapgpt-3.5-turbo-0125model does not have the vision capability.
parseOpenAIResponse method - to parse the JSON response
private static String parseOpenAIResponse(JsonObject responseJson) {
try {
JsonObject message = responseJson.getJsonArray("choices").getJsonObject(0).getJsonObject("message");
String content = message.getString("content");
int totalTokens = responseJson.getJsonObject("usage").getInt("total_tokens");
return content + "," + totalTokens;
} catch (Exception e) {
e.printStackTrace();
return "N/A,N/A,N/A,N/A";
}
}- The JSON response contains a list of replies, from the first entry of which we extract the message with image analysis.
- The extracted content, expected in comma-separated format, is combined with the
total_tokensvalue from theusagesection to track the API call's cost.
analyseImage method - to be called from Oracle database
public static String analyseImage(String prompt, String apiKey, Clob base64Image) throws IOException {
try {
String base64Data = convertClobToString(base64Image);
String openAiEndpoint = "https://api.openai.com/v1/chat/completions";
JsonObject payload = createOpenAIRequestPayload(prompt, base64Data);
HttpURLConnection connection = (HttpURLConnection) new URL(openAiEndpoint).openConnection();
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json");
connection.setRequestProperty("Authorization", "Bearer " + apiKey);
connection.setDoOutput(true);
try (OutputStream os = connection.getOutputStream()) {
os.write(payload.toString().getBytes(StandardCharsets.UTF_8));
}
int responseCode = connection.getResponseCode();
if (responseCode != HttpURLConnection.HTTP_OK) {
throw new IOException("Unexpected code " + responseCode);
}
try (JsonReader reader = Json.createReader(new InputStreamReader(connection.getInputStream(), StandardCharsets.UTF_8))) {
JsonObject responseJson = reader.readObject();
return parseOpenAIResponse(responseJson);
}
} catch (SQLException e) {
e.printStackTrace();
return "N/A,N/A,N/A,N/A";
}
}- Receives the text prompt and the encoded image as inputs along with the OpenAI API key.
- This API call is very similar to the previous text in-text out calls.
Deploying to Oracle Database
Upon compiling the OpenAI class, we package the resulting JAR file and deploy it to the Oracle database, as detailed in a prior blog post. After successful deployment, we register a new function named OPENAI_ANALYSE_IMAGE like this:
CREATE OR REPLACE FUNCTION OPENAI_ANALYSE_IMAGE(prompt IN VARCHAR, apiKey IN VARCHAR, base64Image IN CLOB) RETURN VARCHAR AS
LANGUAGE JAVA NAME 'OpenAI.analyseImage(java.lang.String, java.lang.String, java.sql.Clob) return java.lang.String';Notably, the java.sql.Clob type effectively maps to Oracle's native CLOB data type within this function signature.
Giving Vision to Oracle Database
We can now use the new function in an SQL query to process image data from the previously created table. The query will pass the data to OpenAI through the function and update specific table columns with the classified results. As a recap, the table structure is as follows:
CREATE TABLE CAR_IMAGE_RECOGNITION (
ID NUMBER(10,0) PRIMARY KEY,
CAR_IMAGE_BASE64 CLOB NOT NULL,
CAR_MAKE VARCHAR(250 CHAR) NULL,
CAR_MODEL VARCHAR(250 CHAR) NULL,
CAR_COLOUR VARCHAR(250 CHAR) NULL,
TOKENS_SPENT NUMBER(10,0) NULL
);
Recall that we populated the first two columns (ID and CAR_IMAGE_BASE64) in the previous blog post.
The SQL statement that calls the OPENAI_ANALYSE_IMAGE function and updates the CAR_IMAGE_RECOGNITION table with the results:
MERGE INTO CAR_IMAGE_RECOGNITION TARGET_TABLE
USING (
WITH
Q_SOURCE AS (
SELECT
ID,
OPENAI_ANALYSE_IMAGE('Please identify the make, model, and colour of the car shown in the image. (If fictional, use the the closest to make and model you can come up with.) Respond with concise answers in the format: make, model, colour. Example: "Toyota, Corolla, Blue". There should be exactly two commas in the reply. Make, model and colour names should not contain commas.', '<INSERT YOUR API KEY HERE!!!>', CAR_IMAGE_BASE64) FROM_OPENAI
FROM CAR_IMAGE_RECOGNITION
),
Q_EXTRACT AS (
SELECT
ID,
TRIM(REGEXP_SUBSTR(FROM_OPENAI, '[^,]+', 1, 1)) AS MAKE,
TRIM(REGEXP_SUBSTR(FROM_OPENAI, '[^,]+', 1, 2)) AS MODEL,
TRIM(REGEXP_SUBSTR(FROM_OPENAI, '[^,]+', 1, 3)) AS COLOUR,
TRIM(REGEXP_SUBSTR(FROM_OPENAI, '[^,]+', 1, 4)) AS TOKENS_SPENT
FROM Q_SOURCE
)
SELECT
ID,
MAKE,
MODEL,
TRIM(TRIM(TRAILING '.' FROM COLOUR)) COLOUR, -- remove trailing dots
CASE WHEN REGEXP_LIKE(TOKENS_SPENT, '^-?\d+(\.\d+)?$') THEN TO_NUMBER(TOKENS_SPENT) ELSE -1 END TOKENS_SPENT -- convert to number
FROM Q_EXTRACT
) SOURCE_TABLE
ON (TARGET_TABLE.ID = SOURCE_TABLE.ID)
WHEN MATCHED THEN
UPDATE SET
TARGET_TABLE.CAR_MAKE = SOURCE_TABLE.MAKE,
TARGET_TABLE.CAR_MODEL = SOURCE_TABLE.MODEL,
TARGET_TABLE.CAR_COLOUR = SOURCE_TABLE.COLOUR,
TARGET_TABLE.TOKENS_SPENT = SOURCE_TABLE.TOKENS_SPENT;Note the extensive prompt, which emphasises a specific return data format. The AI may struggle to adhere to this requested format, particularly when dealing with atypical input data.
The Result
We can now select from the CAR_IMAGE_RECOGNITION table to see the results. But first, let us remind ourselves what the input data looks like:

For the above set of cars, we are asking for make, model and colour.
Let us now see how well the GPT-4o can handle that task:
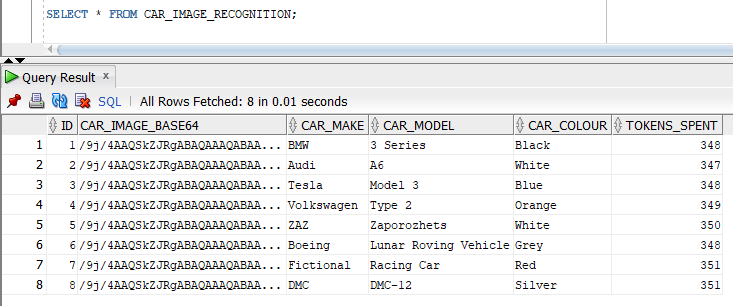
It is hard to find fault in the above. If we are being picky:
- the DMC DeLorean production model was never called the DMC-12, that name was used for the pre-production model only,
- the Volkswagen Type 2 (Car 4) is white and orange, not just orange,
- the official model name of Car 5 is ZAZ-968, though it was very commonly referred to as "Zaporozhets",
- the Car 7 is Lightning McQueen from "Cars" but that is the car's name, not the model name so GPT-4o might be right not to use that as the model name.
The GPT-4o has done a very good job.
Now, let us replace the size- and quality-optimised images with the much bigger original images in the CAR_IMAGE_RECOGNITION table and re-run the analysis query above. Do we get a better result from GPT-4o with bigger images?
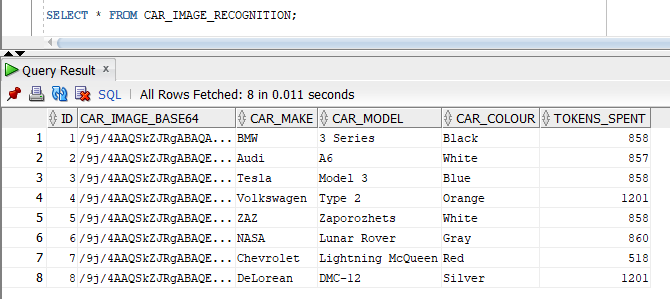
The results between the optimized and original images are comparable, with neither demonstrating a clear superiority. Notably, Lightning McQueen is identified as a Chevrolet, aligning with its visual resemblance to the Chevrolet Corvette. The maker of the Lunar Rover is now NASA, which is not as good an answer as Boeing but still passable.
A key distinction lies in token expenditure. As discussed previously, optimised images constitute a mere 3% of the originals' byte size. However, while the processing cost is under half that of the originals, the disparity isn't as substantial as the file size difference. Furthermore, processing the eight optimised images in SQL Developer took slightly over 70 seconds, compared to over 160 seconds for the originals. It was definitely worth optimising the input images but the difference is not as dramatic as the size difference might suggest.
Let us now address the pressing concerns.
Is it worth it?
Unlike text in-text out analysis, image analysis takes more time and costs much more.
The Cost
OpenAI offers two vision-capable models, GPT-4 and GPT-4o, with input costs of US$10.00/1M tokens and US$5.00/1M tokens respectively. Notably, GPT-4o, while newer and more capable, is half the cost of GPT-4.
Based on our small set of experimental data, analysing 1000 optimised images with GPT-4o would cost approximately US$1.75, while analysing 1000 original size and quality images would be around US$4.50. The optimised image cost estimate is more reliable because optimisation resizes all images down to the same thumbnail size and quality, implying similar byte size.
It is important to note that these are estimates based on current pricing and usage. For enterprise clients, costs may vary significantly depending on volume discounts, future model pricing, and specific agreements with OpenAI. Additionally, while the older GPT-3.5-turbo model is considerably cheaper, it lacks vision capabilities.
The Speed
The 8 optimised images were processed in 70 seconds, which means sequential processing is not a good option for large data volumes. Parallel processing can address that issue, however, depending on your account tier, you are subject to rate limits. You can check the limits for your account by following this link or check the OpenAI Rate Limits Guide. For GPT-4o, Tier 1 the limit is 500 requests per minute and 30,000 tokens per minute, which translates to the maximum of about 86 optimised images processed per minute. Tier 5 allows up to 10,000 requests and 5,000,000 tokens per minute, which translates to a maximum of 10,000 images per minute.
Alternative: train a bespoke neural network
Large Language Models (LLMs) are not the universal solution to any data processing challenge. For tasks with an already available labelled data set, training a custom neural network may be more efficient and cost-effective in the long run, albeit with initial development and maintenance requirements.
Alternatively, a hybrid approach could leverage a custom neural network for most cases, reserving the commercial LLMs for a subset of input data where the custom model falters.
Alternative: manage parallelism outside the Oracle database
When time-sensitive processing of extensive data necessitates parallelism, it is better to manage the degree of parallelism outside the relational database environment, for example within a Python script.
Conclusion
Directly integrating OpenAI models within Oracle Database is not only feasible but opens up exciting possibilities for image analysis and classification, a task previously considered challenging if at all possible. Recent advancements in Large Language Models (LLMs) have demonstrated their remarkable proficiency in this domain. Consequently, the question is no longer about feasibility but rather about determining the most effective solution. LLMs present a compelling option, provided we carefully consider and address the inherent challenges related to cost and performance optimisation.