Tip Tuesday | Build and Analyse Network Graphs in Minutes with Python's NetworkX

Python's NetworkX library offers a simple yet powerful entry point into the world of network graph construction and analysis.
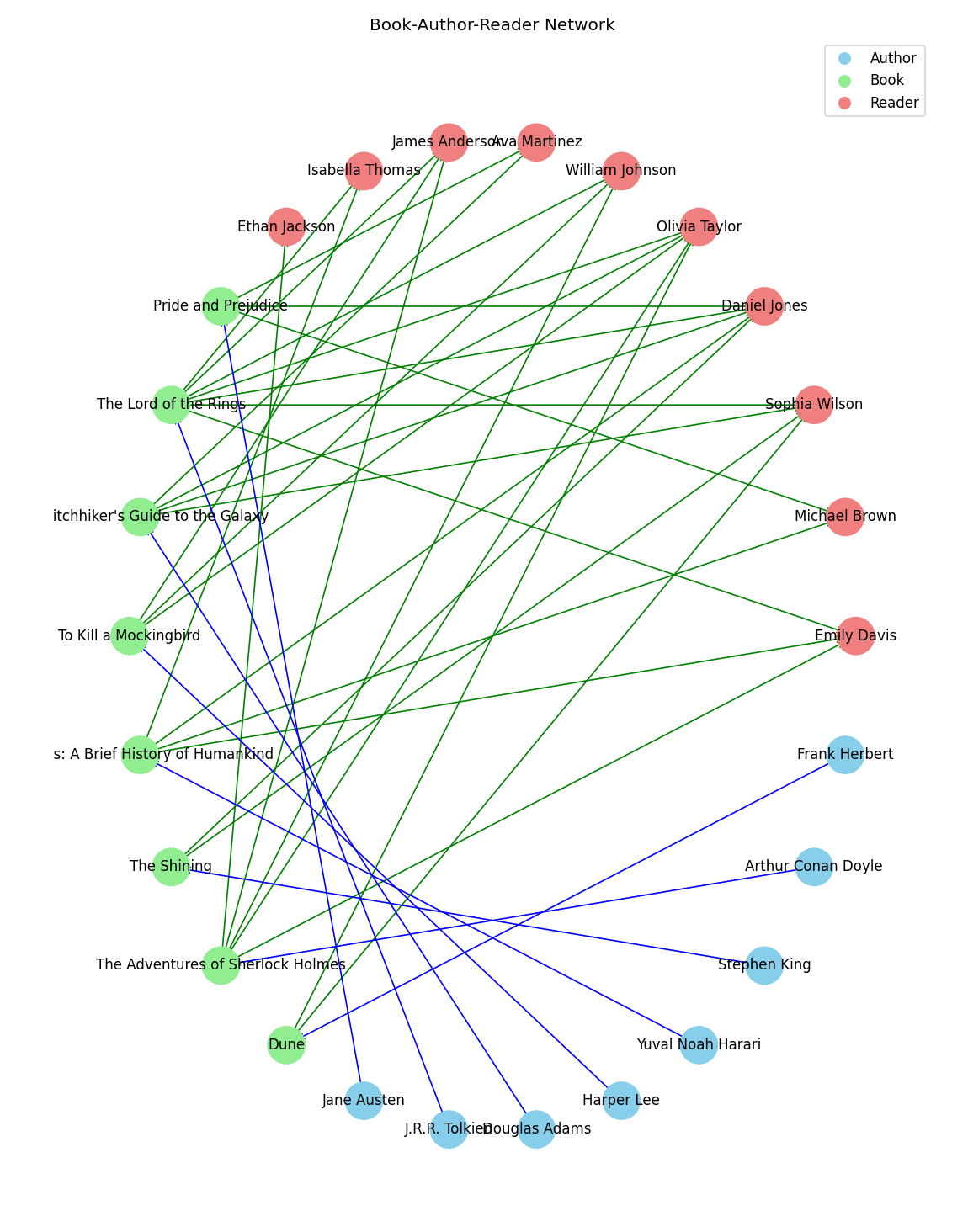
Let us build a directional graph with three types of nodes, similar to entities in a relational database:
- Author,
- Book,
- Reader.
import networkx as nx
G = nx.DiGraph()
authors = ["Jane Austen", "J.R.R. Tolkien", "Douglas Adams", "Harper Lee", "Yuval Noah Harari", "Stephen King", "Arthur Conan Doyle", "Frank Herbert"]
for author in authors:
G.add_node(author, type="author")
books = [
("Pride and Prejudice", "Romance"),
("The Lord of the Rings", "Fantasy"),
("The Hitchhiker's Guide to the Galaxy", "Science Fiction"),
("To Kill a Mockingbird", "Historical Fiction"),
("Sapiens: A Brief History of Humankind", "Nonfiction"),
("The Shining", "Horror"),
("The Adventures of Sherlock Holmes", "Mystery"),
("Dune", "Science Fiction")
]
for book, genre in books:
G.add_node(book, type="book", genre=genre)
book_titles = [book[0] for book in books]
readers = ["Emily Davis", "Michael Brown", "Sophia Wilson", "Daniel Jones", "Olivia Taylor", "William Johnson", "Ava Martinez", "James Anderson", "Isabella Thomas", "Ethan Jackson"]
for reader in readers:
G.add_node(reader, type="reader")Next, we will establish relationships between authors and their books, and between books and their readers, using directed edges. Due to the directional nature of our graph, the order of nodes within each edge definition is significant.
G.add_edge("Jane Austen", "Pride and Prejudice", type="writes")
G.add_edge("J.R.R. Tolkien", "The Lord of the Rings", type="writes")
G.add_edge("Douglas Adams", "The Hitchhiker's Guide to the Galaxy", type="writes")
G.add_edge("Harper Lee", "To Kill a Mockingbird", type="writes")
G.add_edge("Yuval Noah Harari", "Sapiens: A Brief History of Humankind", type="writes")
G.add_edge("Stephen King", "The Shining", type="writes")
G.add_edge("Arthur Conan Doyle", "The Adventures of Sherlock Holmes", type="writes")
G.add_edge("Frank Herbert", "Dune", type="writes")
G.add_edge("Pride and Prejudice", "Michael Brown", type="reads")
G.add_edge("Pride and Prejudice", "Daniel Jones", type="reads")
G.add_edge("Pride and Prejudice", "Ava Martinez", type="reads")
G.add_edge("The Lord of the Rings", "Emily Davis", type="reads")
G.add_edge("The Lord of the Rings", "Sophia Wilson", type="reads")
G.add_edge("The Lord of the Rings", "Daniel Jones", type="reads")
G.add_edge("The Lord of the Rings", "Olivia Taylor", type="reads")
G.add_edge("The Lord of the Rings", "William Johnson", type="reads")
G.add_edge("The Lord of the Rings", "James Anderson", type="reads")
G.add_edge("The Lord of the Rings", "Isabella Thomas", type="reads")
G.add_edge("The Hitchhiker's Guide to the Galaxy", "Sophia Wilson", type="reads")
G.add_edge("The Hitchhiker's Guide to the Galaxy", "Daniel Jones", type="reads")
G.add_edge("The Hitchhiker's Guide to the Galaxy", "Olivia Taylor", type="reads")
G.add_edge("The Hitchhiker's Guide to the Galaxy", "Ava Martinez", type="reads")
G.add_edge("To Kill a Mockingbird", "Olivia Taylor", type="reads")
G.add_edge("To Kill a Mockingbird", "William Johnson", type="reads")
G.add_edge("To Kill a Mockingbird", "James Anderson", type="reads")
G.add_edge("Sapiens: A Brief History of Humankind", "Emily Davis", type="reads")
G.add_edge("Sapiens: A Brief History of Humankind", "Michael Brown", type="reads")
G.add_edge("Sapiens: A Brief History of Humankind", "Daniel Jones", type="reads")
G.add_edge("Sapiens: A Brief History of Humankind", "Isabella Thomas", type="reads")
G.add_edge("The Shining", "Sophia Wilson", type="reads")
G.add_edge("The Shining", "Daniel Jones", type="reads")
G.add_edge("The Adventures of Sherlock Holmes", "Emily Davis", type="reads")
G.add_edge("The Adventures of Sherlock Holmes", "Olivia Taylor", type="reads")
G.add_edge("The Adventures of Sherlock Holmes", "William Johnson", type="reads")
G.add_edge("The Adventures of Sherlock Holmes", "James Anderson", type="reads")
G.add_edge("The Adventures of Sherlock Holmes", "Ethan Jackson", type="reads")
G.add_edge("Dune", "Sophia Wilson", type="reads")
G.add_edge("Dune", "Olivia Taylor", type="reads")The graph now represents the following relationships: Authors create Books, which are then read by Readers.
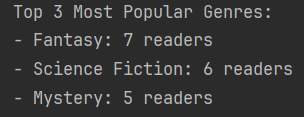
Now let us do a few searches. First, we want to query the above graph for the Top 3 most popular Book genres. (We will use the Counter collection for that: from collections import Counter.)
def analyse_genre_popularity(G):
genre_counts = Counter()
for book in book_titles:
genre = G.nodes[book]['genre']
readers = [node for node in G.successors(book) if G.nodes[node]['type'] == 'reader']
genre_counts[genre] += len(readers)
top_genres = genre_counts.most_common(3)
print("\nTop 3 Most Popular Genres:")
for genre, count in top_genres:
print(f"- {genre}: {count} readers")
analyse_genre_popularity(G)Because the graph is directional, we can use the Book notes successors method to get all its Readers.
The result looks like this:
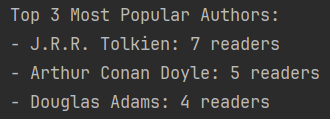
Next, let us search for the Top 3 most popular Authors measured by the number of Readers:
def analyse_author_popularity(G):
author_counts = Counter()
for author in authors:
readers = set()
for book in G.successors(author):
readers.update(node for node in G.successors(book))
author_counts[author] += len(readers)
top_authors = author_counts.most_common(3)
print("\nTop 3 Most Popular Authors:")
for author, count in top_authors:
print(f"- {author}: {count} readers")
analyse_author_popularity(G)Firstly, we must traverse the graph in two distinct steps: from Author to Book, then from Book to Reader. It is important to note that multiple books can be written by a single author, and multiple books can be read by the same reader. To avoid double-counting readers, we use a set to collect unique readers for each author. The final count of readers is determined only after all relevant books have been processed.
This is the result:
Next, let us search for the Top 3 Readers familiar with most Authors:
def analyse_reader_familiarity(G):
reader_familiarity = Counter()
for reader in readers:
books_read = G.predecessors(reader)
authors_read = set()
for book in books_read:
authors_read.add(G.predecessors(book))
reader_familiarity[reader] = len(authors_read)
top_readers = reader_familiarity.most_common(3)
print("\nTop 3 Readers Familiar with Most Authors:")
for reader, count in top_readers:
print(f"- {reader}: Read books by {count} authors")
analyse_reader_familiarity(G)This is very similar to the previous example, except the traverse direction is opposite - therefore we are now using the predecessors method.
The output is:

NetworkX is an excellent library for easily creating and analysing network graphs. While other Python libraries offer more advanced capabilities and performance, particularly in visualisation, NetworkX remains a suitable choice for many use cases due to its simplicity and versatility.