Oracle Analytics AI Assistant: An Exploration


The highly anticipated Oracle Analytics Gen-AI feature—the Oracle Analytics AI Assistant—has finally arrived! After eagerly awaiting the opportunity to test this capability since its announcement at Oracle CloudWorld 2023, I was thrilled to gain access in early September to build a solution preview integrating this feature for Oracle CloudWorld 2024; and more excitedly – demonstrating to customers. In this article, I’ll explore the possibilities and limitations of this exciting new feature.
In today’s world of intuitive analytics, imagine having a personal assistant embedded within your BI platform, ready to deliver instant answers to your most complex analytical queries, all drawn from your datasets and workbooks. The new Oracle Analytics AI Assistant enhances the already integrated AI/ML capabilities that elevate the user experience.
To explore this new feature, follow the steps outlined below. For the demonstration, I will be using the 2024 World Population Dataset.
#1: Creating a New Dataset
I have created a brand-new dataset in OAC, using the downloaded World Population data file and created a new workbook on top of it.
#2: Accessing AI Assistant
If you click on the light bulb and access the Insights panel, you will now see an additional ‘Assistant’ tab with ‘Insights’.
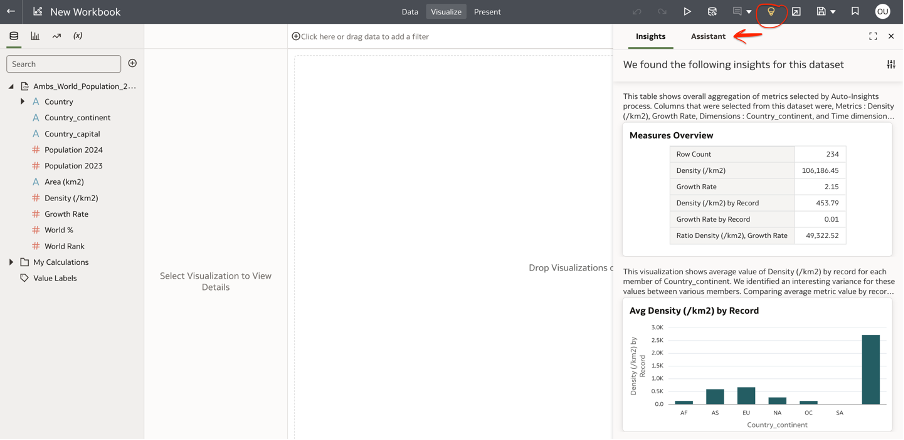
If indexing is not enabled on the dataset, you'll see a notification in the Assistant tab stating: 'Assistant is currently disabled because all datasets are being trained or indexing is disabled.'
The interface will then prompt you to access the Search tab within the Dataset Inspector.
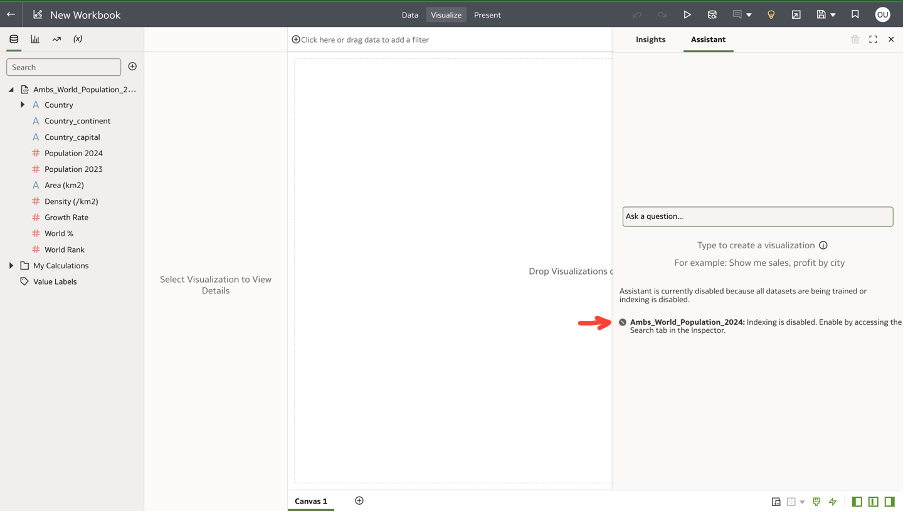
#3: Enable Indexing for the Dataset
Right-click your dataset and select Inspect, to access the dataset inspector and click on the Search tab highlighted below.
In the Search tab, you can either choose ‘Assistant’ or ‘Assistant and Homepage Ask’ – based on your requirements.
I have selected ‘Assistant and Homepage Ask’ since I want to enable both Homepage Ask and the Assistant.
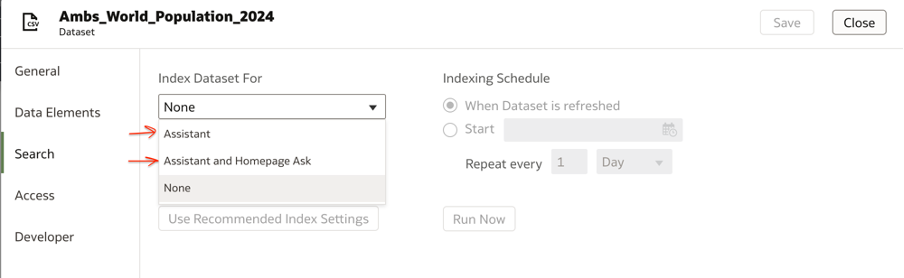
When you make this selection, as you can see below – the default recommended indexing settings will be enabled for all the attributes in the dataset.
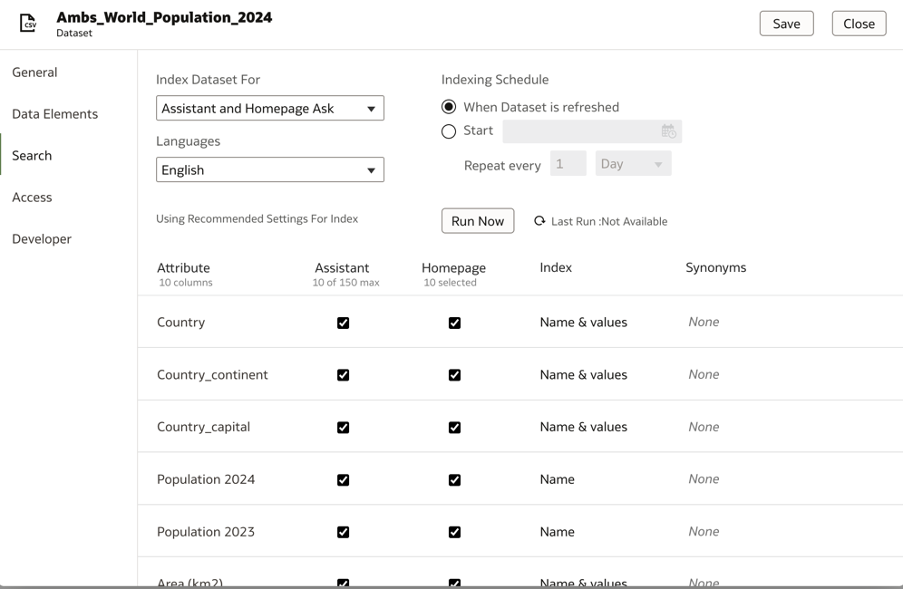
The indexing can be done on the attribute ‘Name’ or ‘Name & Values’. It is interesting to note that for measures, the Index option is available only for the Name and not the values.
You also have the option to map synonyms to the attributes to train the model to identify any different references to the names. For now, I am going to experiment with the default settings.
The Indexing Schedule can be set to either:
o ‘When Dataset is Scheduled’, or
o Start from a chosen date and set to repeat every specified day/hour/week.
Once set, click on Save and Run Now, and the indexing will be initiated as configured.

I have executed the indexing as starting on the current date and set it to repeat every 1 hour.
When the indexing is in progress, you can check the indexing status from the Assistant tab from the workbook, using the Check Status option.
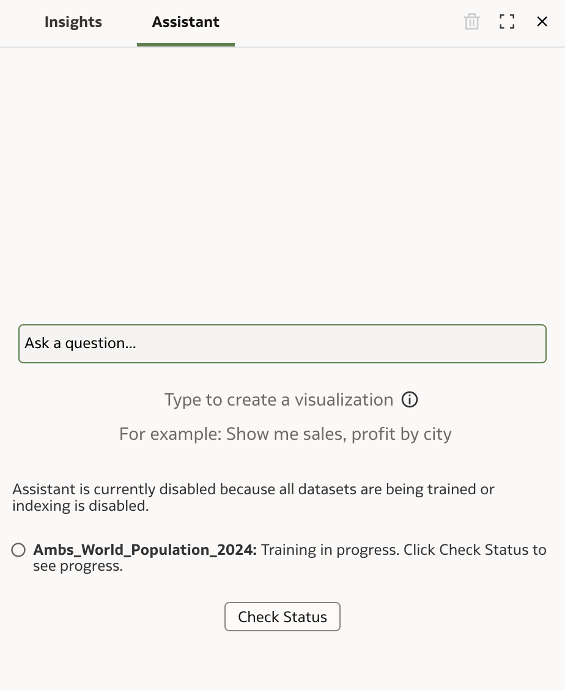
Once the indexing is completed, you are all set to ask questions to your AI Assistant.
And the fun begins!
#4: Converse with your Assistant!
My goal in testing the conversations was to experiment with various aspects of the capability in detail, to gain a deeper understanding of its functionality.
Experiment 1: Visualisations
I started conversing with an obvious question with respect to the World Population dataset being analysed.
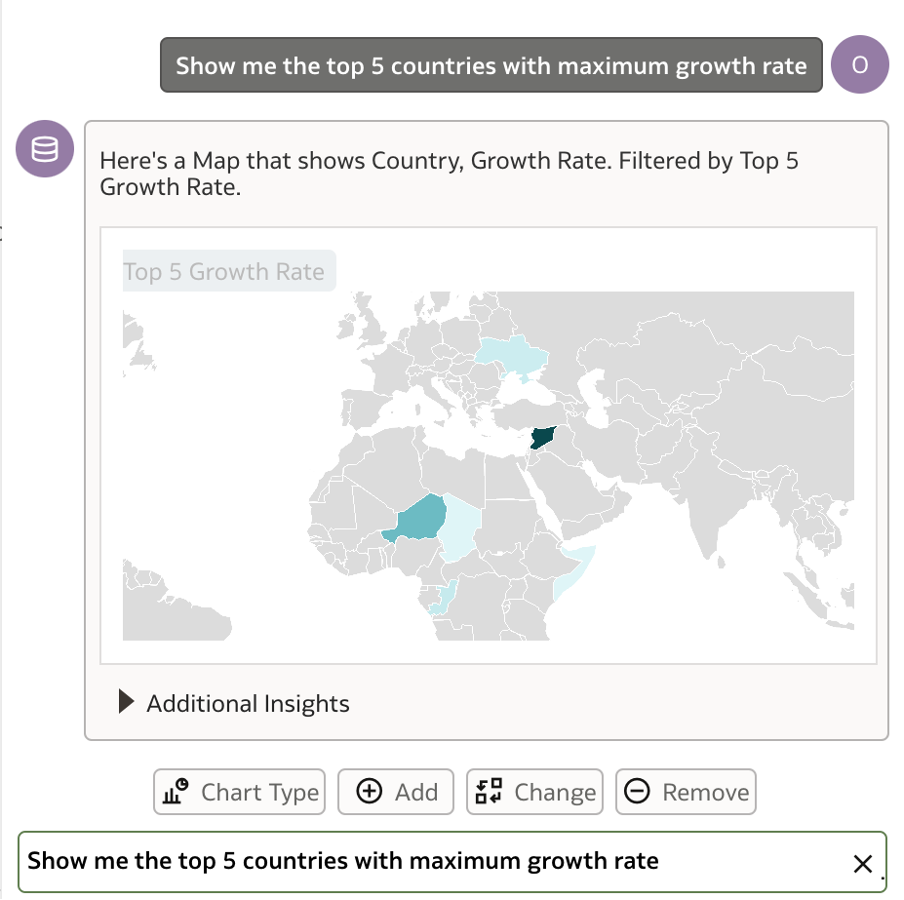
I ask the assistant – ‘Show me the top 5 countries with maximum growth rate’
Interestingly, a map visualisation is generated depicting the top 5 countries.
Clicking on the Chart Type button, I select Bar. This auto-populates the command as below:

Click on Enter and there you go!
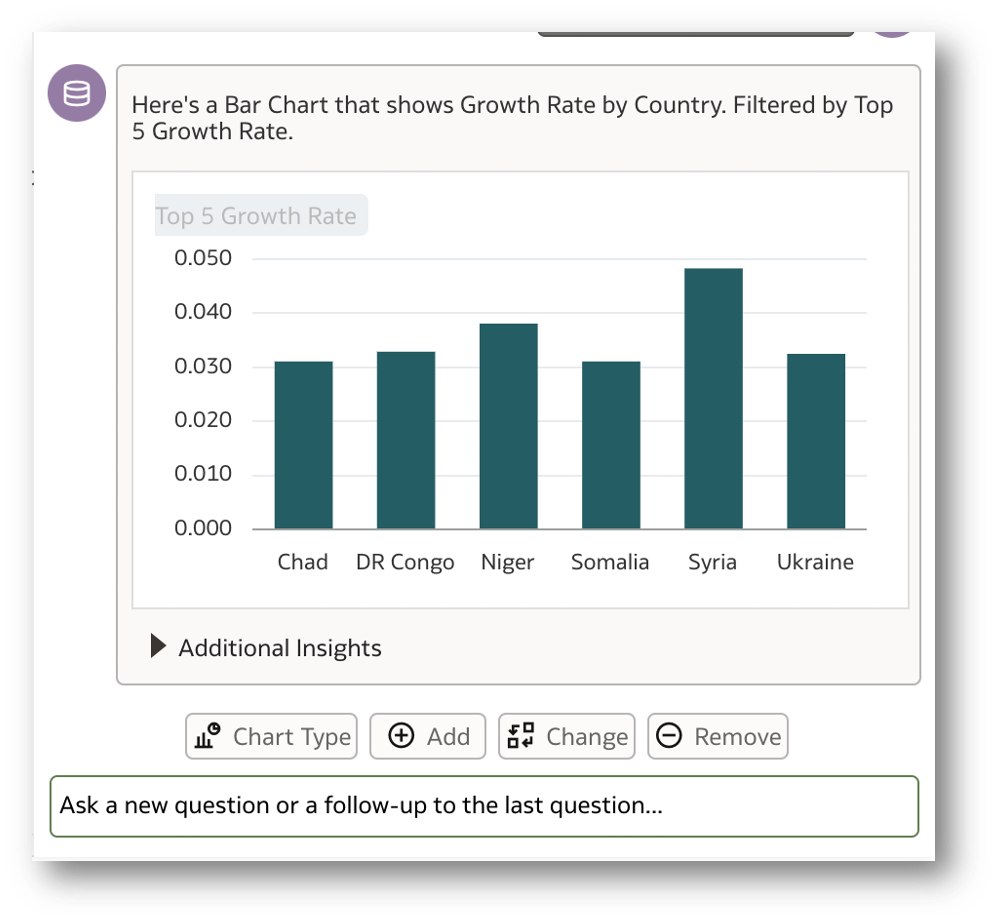
This is impressive!
I also tried asking the question differently as ‘Show me a map visualisation showing growth rate of different countries’. This gave a clean map visualisation as shown below.
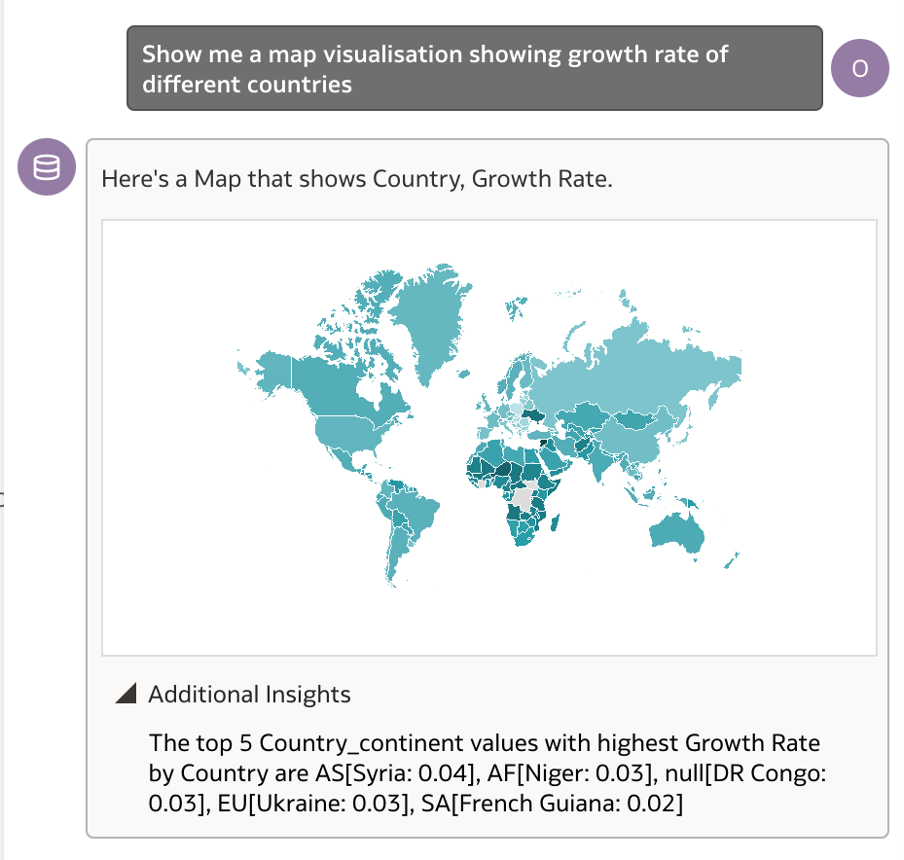
Am happy so far!
Please note, once a result or visualisation is generated, the Chart Type option lets you change it to any of the following 23 options.
o Bar
o Stacked Bar
o 100% Stacked Bar
o Horizontal Bar
o Horizontal Stacked
o Horizontal 100% Stacked Bar
o Waterfall
o Line
o Area
o Stacked Area
o Radar Line
o Radar Area
o Radar Bar
o Scatter
o Pie
o Donut
o Treemap
o Pivot
o Table
o Grid Heat Map
o Tile
o Map
o Language Narrative
Experiment 2 – Power of Synonyms
Next, I would like to quiz the assistant with references not directly linked to the column references in the table.
To trick the Assistant, instead of including the direct reference of ‘Country’, added ‘County’ to make it sound similar and confuse further.

Looks like the Assistant has rightly taken the ‘county’ as a different attribute and prompted for the question to be rephrased.
Now this is the perfect opportunity for us to experiment with the power of synonyms.
For the experiment’s sake, I went back and added a new synonym for the attribute Country as ‘county’ and re-indexed the dataset.

And there you go; the question now finds its correct answer!
Wherever further tuning is required, this gives me the confidence that the AI Assistant is capable of mapping the synonyms correctly to related user inputs.
Experiment 3: Indexing Options
I made an early reference to the fact that for measures, the Index option is available only for the Name and not the Values. Let me demonstrate what I meant by that.
Population 2023 and Population 2024 are two columns in the dataset that are currently mapped as a Measure. If you look at the indexing settings for these fields, you will notice that the Index option for it only shows ‘Name’.

Experimenting further, I go back to the dataset editor and convert the Population 2023 and Population 2022 from Measure to Attribute. Save the dataset and run the indexing again.
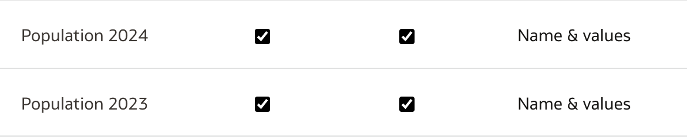
Now, I can see both the Indexing options for the attribute as below.

I went ahead and chose Name & values for both columns, saved and clicked on Run Now for re-indexing with the applied changes.
Let us dive a bit deeper, asking different questions based on columns with Name and Name & Value indexes.
Let us consider the measures in the dataset which has the index mapping only with ‘Name’.
o Density (/km2)
o Growth Rate
o World
o World Rank%
A straightforward question on the growth rate has fetched clear results.
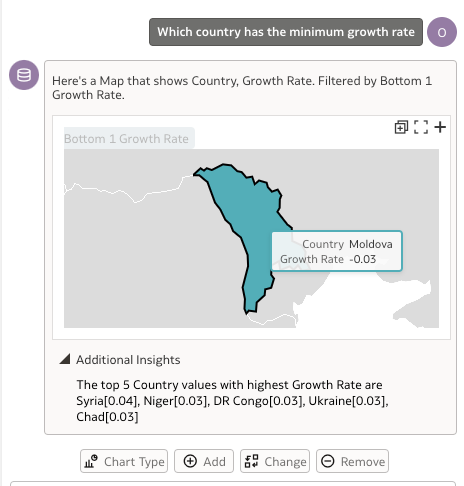
Trying to fetch the value of growth rate separately for the country Moldova also fetched me the right results.
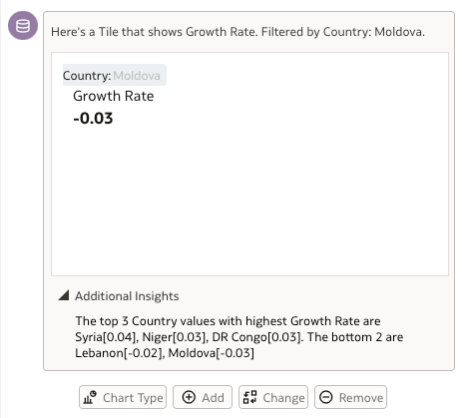
If you check the Additional Insights, even when Moldova is not specified to have the lowest growth rate in the latest question, the insight detects the countries with the highest growth rate here.
Let us now move onto the Attribute columns in the datasets to test the fields indexed based on ‘Name & Value’. The applicable attributes are:
o Country
o Country_continent
o Country_capital
o Population 2024
o Population 2023
o Area (km2)
I ask the assistant – ‘What are the countries having maximum area’.
Strangely, the result showed me the country as the Vatican City which is in fact the smallest.
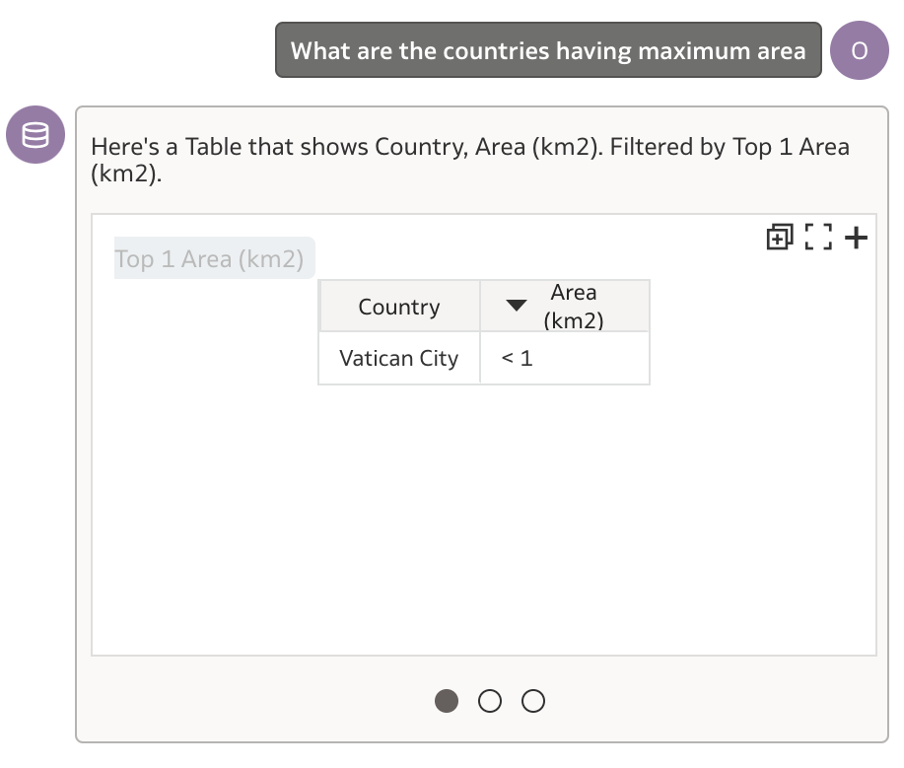
I do not doubt the assistant in this case and go back to check the dataset values to verify.
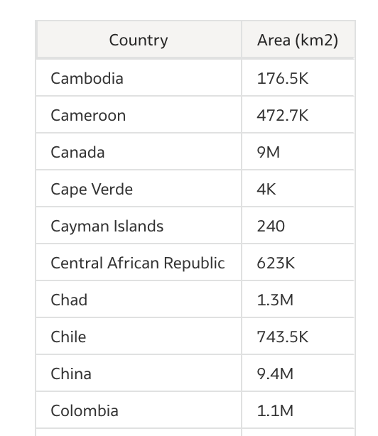
It is noticed that only Vatican City has a value with the ‘<’ notation added to it, which is the root cause for the discrepancy here.
Optimistically, I ask the assistant next – ‘Which country has the maximum Area (km2) other than the Vatican City?’.
Even if I have countries like China having 9.4M km2 recorded, the result is showing me Canada with 9M km2 as the result.
This experiment did not go too well, indeed.
Clearly, more tuning of the feature is required wherever number notations are coming into the picture. Until that happens, data transformations can help us get to the right results.
Just to clarify further, I am picking the field World Rank next, as this has values without notations from 1 to 234.
Dataset tells me that India is set with World Rank as 1 and the Vatican City has the rank as 234. Let us see how the assistant can decipher the information when we converse with it.
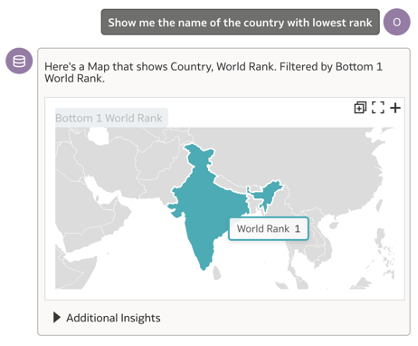
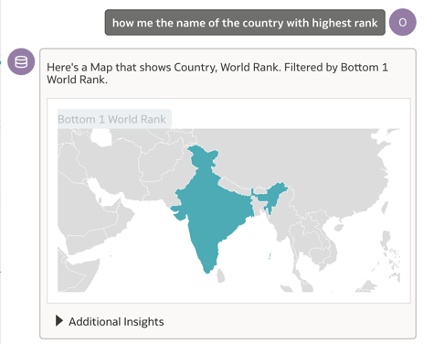
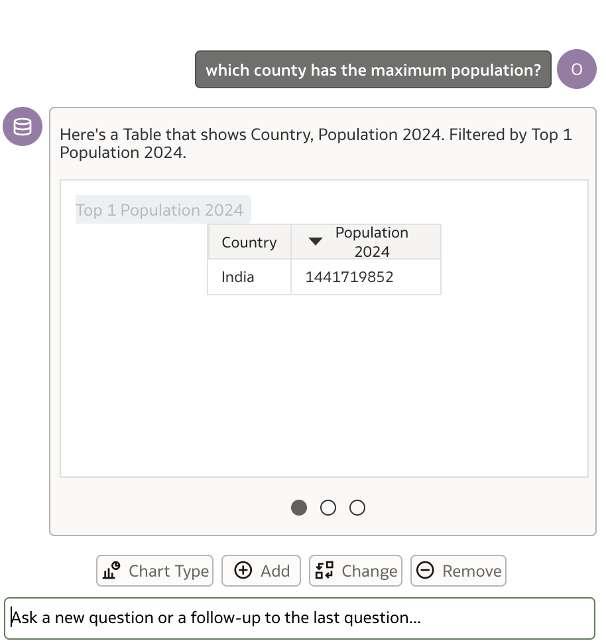
Both my questions asking to show the country with ‘lowest rank’ and ‘highest rank’ are returning the result as India.
Here is the funny part – the Assistant is detecting the lowest value of the World Rank field as 1 – when it returns the first response as India. In the second question, probably the ‘highest rank’ is associated with the ‘best rank’ and returning the same results.
Now, this comes to the user how the question needs to be clearly voiced, to get the the right response.
Experiment 3: Result Accuracy – More Validations
Obviously more curious about accuracy of the results in general, I run additional validations to verify.
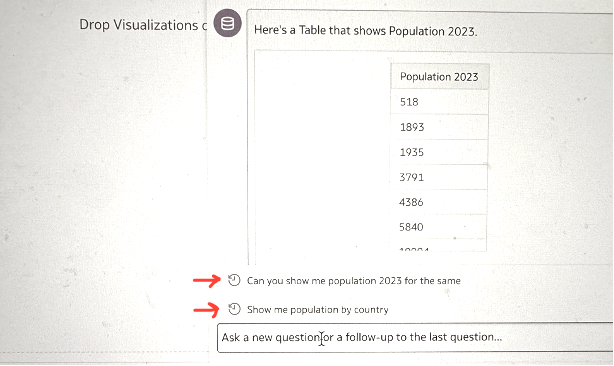
Starting with asking the Assistant – ‘Show me population by country’.
It returns me a table with Population 2024 values fetched against each Country.
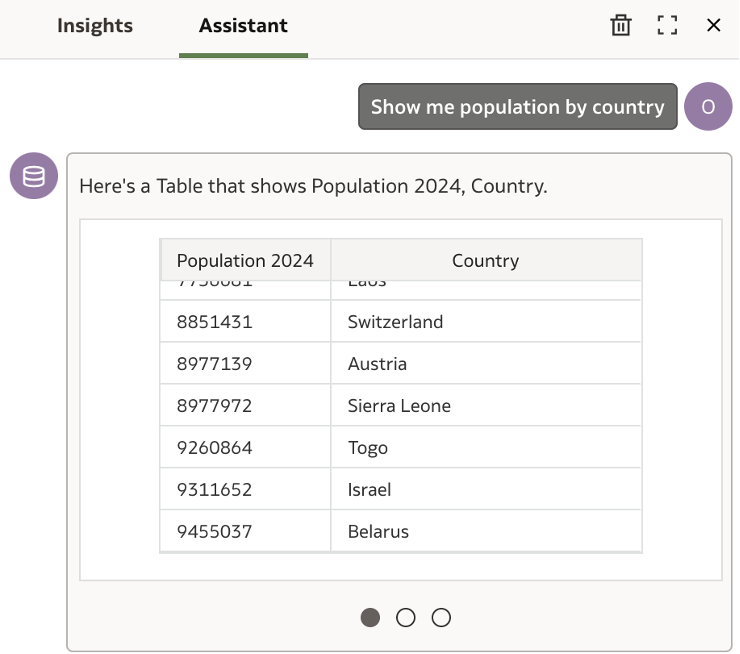
If you think about it, it is surprising how and why the assistant chose to only pick the population values against 2024 here.
To test the behaviour a bit more, I asked a related question to the assistant.
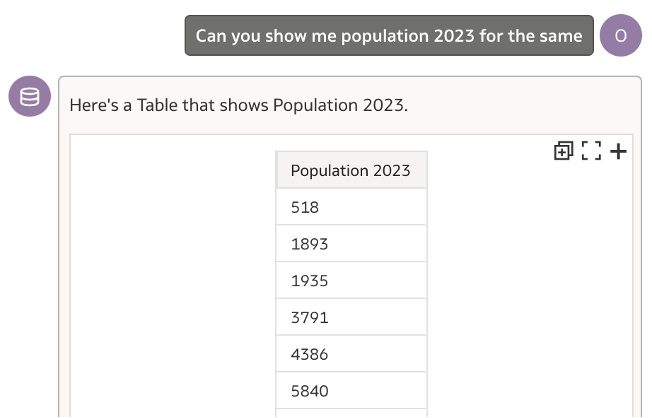
The assistant is returning exactly what is being asked and not following up on the previous question, as would have been wonderful.
However, the interface is prompting the follow-up questions based on the history as shown below.
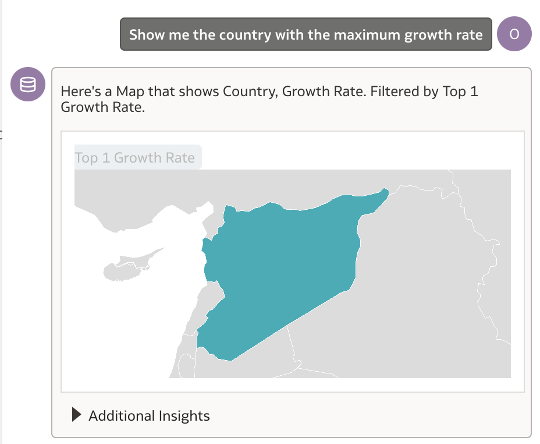
I now went ahead and asked a different question involving finding ‘the country with the maximum growth rate’. The result of this query was spot on and even more exciting to see was the map visualisation generated automatically.
The Additional Insights dropdown option gives information on the bottom 5 countries with the lowest growth rate, which is useful to understand the other side of the spectrum.
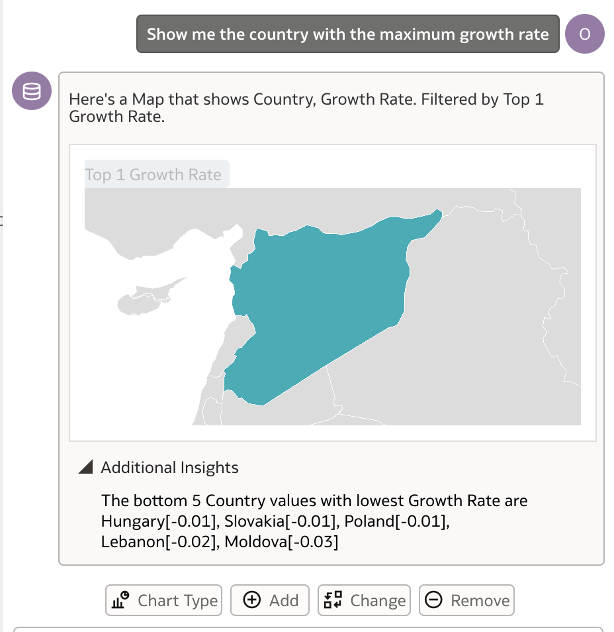
This series of questions and responses boosts confidence in the feature, also highlighting the importance of how queries can be interpreted by the Assistant. It also emphasises the need to phrase questions with minimal ambiguity for clearer results.
Additional Options
The feature also provides additional options to manually Add/ Change/Remove - Fields/ Filters/ Filter Values.
Here is a list of available control options integrated into each generated result, as shown below:

Add Field Options:
o Add Field <columnToAdd>
Add Filter Options:
o Add Filter <filterToAdd>
o Add Filter Value <filterValueToAdd>
Field Change Options:
o Change Field <columnToRemove> with <columnToAdd>
o Change Filter Value <filterValueToRemove> with <filterValueToAdd>
o Change Filter on <filterToRemove> with <columnToAdd>
Remove Field Options:
o Remove Field <columnToRemove>
o Remove Filter <filterToRemove>
o Remove Filter Value <filterValueToRemove>
Let us run a quick test of the field and filter conditions.
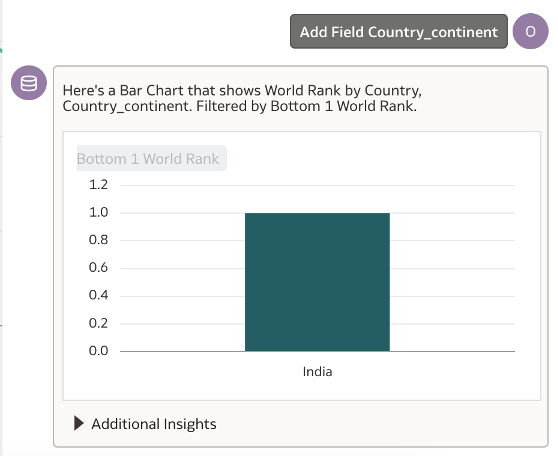
Here you can see that when I added the field Country_continent manually, to the previously generated World Rank visualisation; it generated a Bar Chart showing the World Rank by Country and Country_continent filtered by the highest rank.
Tip: If you add a synonym for Country_continent filed as ‘Continent’, you will be able to refer it in natural language reference itself.
Perfect chance to try out the ‘Remove’ option and I go about adding the condition as ‘Remove Filter World Rank’.
Bingo! This removes the highest rank condition set to the previous visualisation and modifies the bar chart generated to show me World Rank by Countries on a whole.
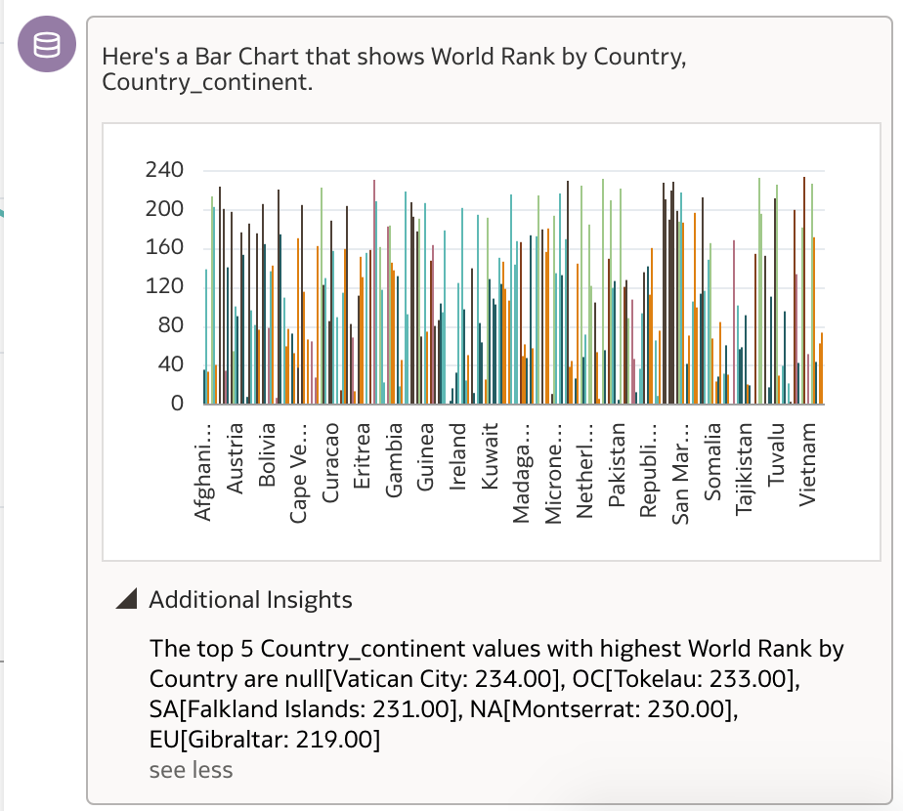
The continent field added previously is still being applied and is deriving additional insights related to it.
Current Limitations
Since this feature leverages an Oracle-managed LLM, it requires tremendous computing and careful planning. This has led Oracle to start the rollout with the largest shapes of 10+ OCPUs across all supported regions. However, the good news is that Oracle has committed to progressively lowering the OCPU requirement over the next several months and ultimately making it available to all customers at no extra cost, at the earliest possible time.
This initial release supports conversing with Datasets, and the Subject Area support will add more power in future releases.
Summary
The Oracle Analytics AI Assistant is a powerful tool for users seeking smarter ways to uncover patterns and answer analytical questions. Powered by a Large Language Model (LLM), it provides pattern-based insights, though users are advised to verify outputs with primary data sources for critical decisions.
Currently, Oracle manages the model, ensuring control over its performance without exposing it to customers. Future plans include continuous model evaluation and potential support for public LLMs via a Bring Your Own License approach.
With a strong foundation and promising refinements, the AI Assistant has met expectations and holds significant potential for future growth.
Want to dive deeper?
In our next post, we'll explore advanced strategies for optimising your data to enhance your conversations with the AI Assistant; including pro tips and examples on indexing.
Stay tuned as we demonstrate how simple yet powerful optimisations can transform the examples discussed in this blog!