Optimising Oracle Analytics AI Assistant: Bring the Intelligence to Life


The rise of conversational AI in analytics promises to make data analytics more accessible to all users. In our previous blog post from last October, we explored the Oracle Analytics AI Assistant feature soon after its release. We walked you through the steps involved in configuring this powerful tool, enabling users to ask complex questions in natural language and receive data-driven responses through automatically generated insights, charts and visualisations. If you missed it, you can access it here and get up to speed.
Since its release, Oracle Analytics AI Assistant has generated a lot of buzz, sparking excitement for its capabilities. Yet, in practice, some users found it fell short of expectations in certain scenarios. But, is this a sign of the feature’s limitations, or is there more at play?
In this blog, I will attempt to dive deeper into the background principles that power the feature, the optimisation strategies and pro tips to unlock the true potential of Oracle Analytics AI Assistant and bring its magic and intelligence to life.
Working Backwards from the Question
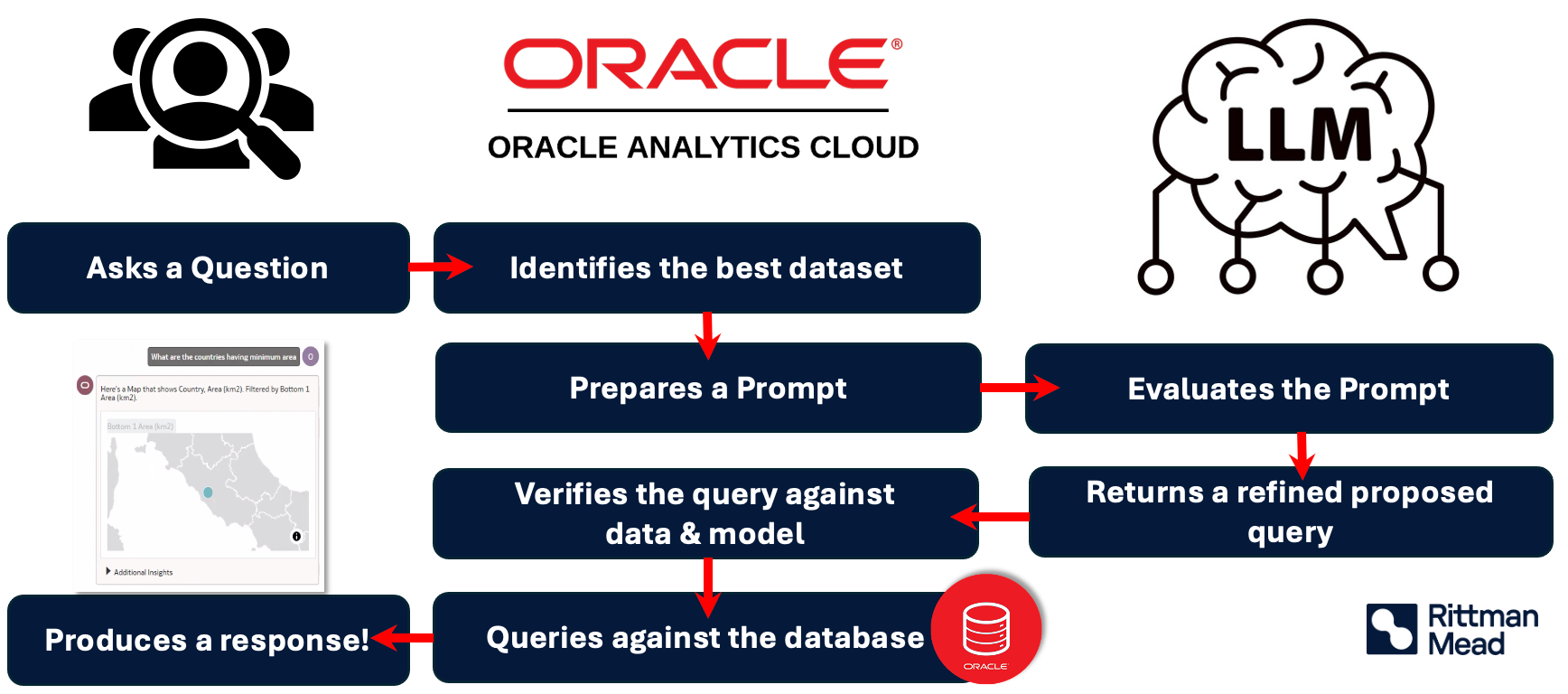
If you have wondered, how exactly is the Assistant able to make sense of the questions asked and respond with meaningful information, the secret lies in its unique “backwards” approach, beginning with the user question. Here is how we can break the process down:
- Question Analysis and Dataset Selection
The process begins when the user submits a question in natural language. The AI Assistant’s first task is to interpret the intent of the question and identify which dataset within the user’s workbook contains the necessary information. By analysing the metadata and attribute values across available datasets, Oracle Analytics Cloud (OAC) selects the dataset/datasets that best match the question’s context.
- Prompt Creation for the LLM
Once the appropriate dataset is selected, OAC constructs a prompt for the Large Language Model (LLM) that includes both the user’s question and pertinent information from the dataset. This prompt typically consists of:
- The natural language question asked by the user
- Metadata from the dataset, including column names, data types, and synonyms
The information encapsulated in the prompt helps the LLM understand the context behind the question, thereby improving the accuracy of the subsequent SQL generation step.
- Query Generation by the LLM
The prompt, when passed to the LLM, interprets it to generate a proposed SQL query, which is typically designed to retrieve the data needed to answer the user’s question. Additionally, the LLM may provide query refinements based on its analysis of the question and dataset structure. The LLM's understanding of the context, informed by both the user question and dataset metadata, is crucial for generating an SQL query that aligns closely with the user’s intent.
- Query Verification and Execution
Once the LLM proposes a SQL query, OAC verifies the query against the data and model to ensure accuracy.
- Database Query and Response Generation
After verification, OAC executes the query on the database and retrieves the result/responses. These are formatted and presented to the user as a graph, or visualisation, completing the natural language query-to-response pipeline.
Tuning Metadata for Optimal AI Performance
Effectively tuning metadata for AI is crucial in ensuring that the Oracle Analytics AI Assistant operates efficiently and accurately when processing user questions. Rather than training the model on the data itself, which can be vast and constantly evolving, Oracle Analytics AI Assistant focuses on training the model based on metadata and indexing strategies. This approach minimises the need for frequent retraining, focusing only on updates when metadata or indexing configurations change. When metadata changes are detected, the model is automatically retrained to reflect these updates in real time, keeping the AI Assistant responsive and up to date.
1. The Role of Indexing
Indexing controls what the users can ask about and provides hints to help the LLM understand your data.
Key Indexing Strategies
To ensure that the Oracle Analytics AI Assistant performs optimally, it is important to understand what types of metadata should be indexed and the implications of indexing choices. Here are some key strategies and best practices:
1. Indexing Unique Identifiers: Always index fields that uniquely identify – such as the keys, product keys, order id, order line id etc. Indexing these unique identifiers can speed up data retrieval and facilitate internal mappings, even if they are not the focus of the user’s question.
2. Names vs. Names and Values: The AI Assistant offers flexibility in how metadata is indexed, specifically with Name and Name & Values indexing:
Indexing on Name: In this approach, only the name of the column is indexed. This basic level of indexing is helpful for measures primarily.
Indexing on Name & Values: This approach goes a step further by indexing both the column name and the values within the column. When values are indexed, the model can map specific entries directly to the correct column, making it easier to create filters based on the exact values.
Example: If the “Country” column is indexed by both Name and Values, and the user asks a question about the “UK,” the AI Assistant can directly filter by the “Country” column using “UK” as a criterion, ensuring a more accurate and targeted response.
3. Limitations on Numeric Fields: For numeric columns, indexing on values is not feasible due to the wide range of possible values. In such cases, indexing focuses on the column name rather than individual values. Thus preventing the model from indexing every possible number, which would be computationally expensive and less beneficial, given the nature of numeric data.
Indexing Schedule: The indexing schedule in Oracle Analytics is primarily responsible for managing auto-complete functionality and ensuring that values appear correctly as suggestions when users type in queries.
Legacy of BI Ask and the Importance of Binary Indexing
Oracle Analytics AI Assistant’s indexing methodology inherits its legacy from the BI Ask with the use of a binary indexing system, which enhances the efficiency of data retrieval.
By using binary indexing, the AI Assistant can quickly access and match values, against persistent binary indexes. This rapid matching process allows the AI to fetch indexed information within milliseconds, providing a faster alternative to querying data tables directly.
2. Role of Synonyms in AI Understanding
The use of synonyms is one powerful technique for enhancing metadata, allowing the AI model to understand alternative names or terms associated with specific data fields. By defining synonyms for columns, updating metadata, and refining prompt design, we can significantly enhance the model’s ability to accurately process natural language queries.
When a synonym is added for a column (for example, using “income” as a synonym for “revenue”), it is treated as part of the dataset's metadata. This update helps the language model (LLM) recognise alternative ways that users might refer to certain data points, enhancing its ability to match questions with the correct columns. This focus on metadata, rather than raw data, allows us to make structural improvements that boost the AI Assistant's understanding without needing to retrain the model for every data change.
The LLM also benefits from updates in metadata, such as the addition or removal of columns, which provide context about the dataset’s structure. However, updates to the data content - such as new orders or customers - don’t require model retraining, keeping the model focused on the dataset's structure rather than its transactional details.
How Synonyms Help the AI Model Understand Data Context
The metadata, including synonyms, is sent to the LLM as an “envelope” that describes the dataset’s purpose and structure.
For example, if a dataset pertains to the world population and contains columns like “Cty” (Country) and “Cap” (Capital), these cryptic abbreviations might obscure the dataset’s purpose. By adding descriptive synonyms and metadata (such as “Country” for “Cty”), the LLM can better interpret that this dataset involves countries, populations, and geographic attributes. This understanding allows the model to intelligently process queries related to countries, continents, and population density.
Descriptive Metadata: A Key to Improved Model Intelligence
The more descriptive the metadata, the better the model can understand the dataset’s topic and domain. In many cases, adding synonyms can refine the AI's comprehension of the dataset; however, renaming columns directly to be more descriptive can provide even greater clarity.
For smaller datasets or prototypes where column renaming is manageable, adjusting metadata directly is recommended. For larger databases, synonyms provide a more practical alternative to renaming columns. Additionally, Oracle Analytics Cloud (OAC) offers a data preparation feature that allows users to rename columns at the metadata level without changing the original data source, making it easy to refine metadata without disrupting raw data integrity.
Synonyms for Disambiguation in Queries
Synonyms are particularly useful for resolving ambiguities in user questions, especially when multiple columns have similar or overlapping meanings. Here are some examples where synonyms enhance accuracy:
1. Date Ambiguity: When a dataset includes multiple date columns (e.g., “Order Date” and “Invoice Date”), a question like “Show me sales by month” may create ambiguity. Synonyms can help clarify which date column is relevant for monthly sales reporting, or at the very least, make it easier for the AI to differentiate between date types.
2. Role-Specific Names: In datasets with columns such as “Person Name 1” and “Person Name 2,” synonyms can help clarify roles by mapping these fields to terms like “Employee Name” and “Manager Name.” This additional context allows the AI Assistant to understand relationships within the data, such as reporting structures or supervisory roles.
3. Implicit Time References: When users ask questions like “last date” or “last summer,” it may be unclear which date column to filter on. In such cases, synonyms can be used to provide a default value and reduce ambiguity.
3. What to Avoid?
1. Special Characters: When tuning metadata for the Oracle Analytics AI Assistant, avoid using special characters in synonyms, as the Assistant may not interpret them correctly.
2. Reserved Words: Additionally, steer clear of reserved words - especially SQL function names like “Average” - as synonyms. Using SQL-reserved terms can create conflicts or misinterpretations during query processing, so it’s recommended to choose alternative terms that won’t interfere with SQL operations.
Pro Tips: Tuning Your Data for Natural Language Queries in Oracle Analytics AI Assistant
To get the best performance out of Oracle Analytics AI Assistant and leverage the capabilities of language models (LLMs), it's essential to enrich your data thoughtfully. Here are some best practices for tuning your data to improve natural language understanding and optimise query accuracy.
1. Use Binning for Better Query Interpretation
Binning numerical values into descriptive categories helps make data more intuitive for natural language queries.
For example, instead of raw sales figures, creating categories like "Small," "Medium," and "Large Orders" helps the Assistant respond accurately to questions like, "How many customers have really large orders?"
Binning is a powerful way to add context that generic voice queries can leverage. Common examples include:
· Customer Segmentation: Silver, Gold, Platinum
· Order Sizes: Small, Medium, Large
· Employee Performance: High, Medium, Low
By setting up these bins, users can easily access grouped insights without needing to specify exact numerical ranges in queries.
2. Create Groupings for Enhanced Context
Groupings add valuable layers to your data, enabling the AI Assistant to respond more intelligently to broad questions. Using data preparation tools, you can create access groups, link related categories, and provide smart suggestions.
For instance:
· Category Grouping: Create a group called "Opiates" to include various related drugs, allowing users to ask about "Opiates" rather than specific drug names.
· Demographic Insights: Use features like Reference Knowledge to add demographic insights. For instance, a dataset with names only could be enriched with gender data, enabling demographic analysis like "30% are women."
Reference Knowledge helps build richer datasets by linking data points to broader categories (e.g., linking countries to continents), providing valuable observations for language models to interpret.
3. Address Null Values with Descriptive Terms
Null values can disrupt natural language queries, so converting them into descriptive terms like “Unknown” or “Not Available” allows the Assistant to handle them gracefully.
This practice ensures that voice queries don’t stumble over missing data and that users receive complete answers.
4. Make Data Descriptive and Verbose
Since natural language models interpret words rather than numbers directly, it’s crucial to make data as descriptive as possible. Adding reference knowledge and verbose descriptions helps the Assistant understand the domain of the data, making it easier for users to ask questions within that context. Descriptive metadata also aids the LLM in recognising domain-specific terminology, improving its ability to respond accurately to questions about the data.
Further Experiments with Previous Hiccups
Applying the best practices and optimisation strategies discussed, I revisited previous scenarios that were not as effective. Let us discuss the main ones here.
Example 1: When the World Population dataset returned the opposite results for the question ‘What are the countries having maximum area’.
Here, the data stored with ‘<’ is converting the symbol to its ASCII value and returning the wrong results.
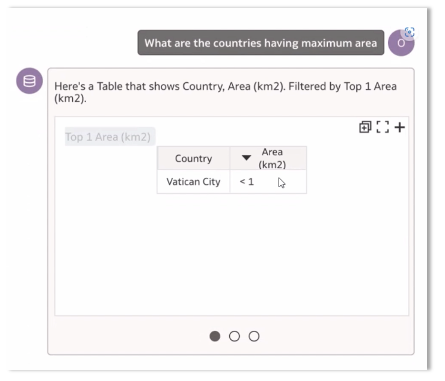
When the data was corrected to its numeric value for Vatican City as 0.44km2 and queried again for maximum and minimum area separately, we got the right responses this time.
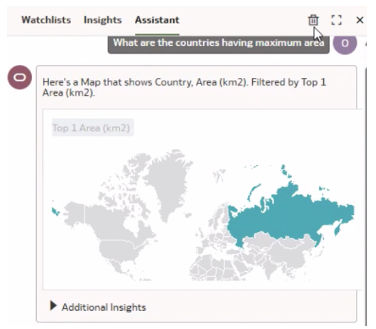
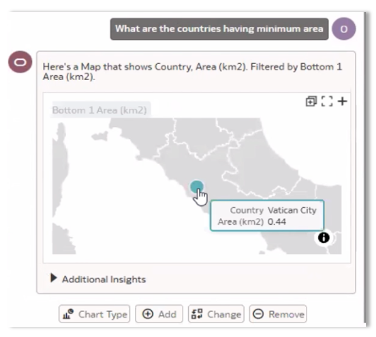
A perfect example to remind us that LLM is not magical in itself without data quality ensured.
Example 2: Here we asked ‘What was the country that ranked the lowest in terms of population’
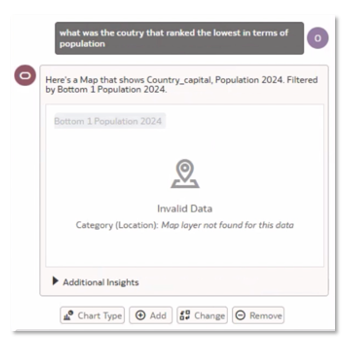
Close examination of the data stored reveals the reason for the Invalid Data response as due to the stored ‘N/A’ value, which was attempted to be plotted on the map as a country and ended up not knowing what to do.
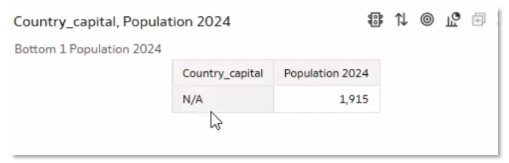
In such scenarios, we could always filter out the unnecessary values by using the +Add option to add a filter.
Exciting New Enhancements Coming Up
The Oracle Analytics AI Assistant is going to be available in two modes:
1) Out-of-the-Box (OOTB)
2) Bring your own LLM (BYOLLM)
The OOTB Assistant will be entirely managed by Oracle and targeted to customer's data specifically. With each customer having their private LLM, the data will 100% private and never shared out of the customer's domain. This is currently being rolled out to larger instances with 10+ OCPUs and will be made available for everyone in the coming months, with no extra cost. The feature is currently applicable to datasets only, however the Subject Areas support is planned from 1H2025.
If you were looking forward to asking questions outside the customer data domain, your go-to feature would be the BYOLLM which is aimed to be made available in 1Q2025. If you have an Open AI license, you need to add the Open AI key into the Oracle Analytics console, and then the power of Open AI and the knowledge residing in the public domain can be additionally harnessed when asking questions to the Assistant. This will be available to all shapes, as Oracle will not be hosting or deploying compute to each customer to host the language models. In terms of data security, rest assured that the data is still not sent to the external LLM, but the questions and, in turn, prompts would be sent to the LLM to return with the respective queries. In future, all top LLMs will be supported under BYOLLM, however, the very first LLM to be supported would be the Open AI GPT4.
Conclusion
Effective metadata tuning is vital for optimising the Oracle Analytics AI Assistant, improving its ability to interpret natural language queries accurately.
Focusing on metadata optimisations and using techniques like indexing, adding synonyms, descriptive column names, and context-enriched metadata helps the Assistant better understand dataset structures and domain-specific terminology, improving accuracy in responses.
Additionally, strategies like binning values, creating relevant groupings, and handling nulls make the data more accessible and interpretable.
In addition, it's essential to ask clear, specific questions and provide relevant context, which enhances its ability to deliver accurate, actionable results. Properly framing queries ensures users receive the most relevant insights from the AI Assistant.
After all, questions are the compass of discovery!
If you’re interested in optimising your use of Oracle Analytics AI Assistant, contact one of our consultants today at info@rittmanmead.com, for help getting started.